Je remercie chaleureusement toutes celles et tous ceux qui m’ont soutenu dans la réalisation de mon mémoire de fin d’étude. Le contexte de travail, à la fois sérieux et détendu, a été particulièrement bénéfique à leur côté.
Une vie professionnelle est en construction constante. J’ai eu la chance d’étudier une première fois l’acoustique il y a 15 ans, puis de travailler en tant qu’administrateur systèmes et réseaux, et enfin de préparer le Diplôme d’État d’Audioprothésiste. Ces expériences multiples sont autant de force pour aborder ma nouvelle carrière.
Je remercie mon maître de stage de troisième année Lydwin Hounkanlin, son assistante Nadège Pécout et sa comptable Christine Polo. La mise en place du 100% Santé m’a permis de vivre, grâce à eux, une montée en compétence intense.
Je remercie les professionnels que sont Xavier Delerce, Christophe Lesimple et Arnaud Génin. Ils ont su me guider, à distance, dans ma pratique de la recherche documentaire.
J’adresse mes remerciements à l’ensemble de l’équipe pédagogique de l’école d’audioprothèse de Bordeaux, notamment Matthieu Del Rio, Damien Bonnard, Luc Forest et Johann Lahai, mais aussi à tous les intervenants qui ont fait cours dans des conditions particulièrement difficiles en cette période de crise sanitaire.
Je pense également à mes maîtres de stage des deux premières années, Marine Le Verge et Vanassa Toubon. Elles ont su me transmettre leur professsionnalisme avec bienveillance. Les patients que j’ai cotoyés pendant ces trois années d’étude ont tout autant contribué à mon apprentissage.
Enfin, j’adresse un clin d’œil à tous les étudiants de l’Université de Bordeaux et des autres écoles d’audioprothèse qui ont su effacer cette petite différence d’âge. J’ai profité d’une seconde jeunesse en leur compagnie.
À ma compagne, mes enfants, mes proches.
Avant-propos
Cette revue de littérature porte sur les méthodes mises en œuvre pour évaluer l’amélioration du rapport signal sur bruit. Dans le contexte sanitaire actuel, les études impliquant les patients sont proscrites. Nous allons nous concentrer sur les aspects techniques, tout en conservant un lien documentaire avec l’anatomie. Le travail présenté ici est issu d’une longue recherche, portant aussi bien sur des publications scientifiques en revues cotées que sur des billets de blog et des discussions plus impromptues avec les professionnels avertis. Après avoir minutieusement analysé les résultats de recherche, nous avons articulé notre écriture autour des questions évoquées dans le titre.
Recherche documentaire, en vue d’une revue systématique
Le moteur de recherche PubMed1 interroge la base de données bibliographiques MEDLINE, administrée par la National Library of Medicine, bibliothèque américaine de médecine. Nous l’avons utilisé avec les critères de requêtes suivants, afin d’identifier les articles répondant à notre sujet, parmi plus 32 millions de citations et de résumés d’articles de recherche biomédicale :
Par ailleurs, des recherches connexes ont été réalisées à partir des bibliographies présentées en fin d’articles, ce qui a permis d’élargir encore la collecte de données. Tous les documents originaux ont été téléchargés depuis la plateforme Babord+ de l’Université de Bordeaux grâce aux PMID, un numéro identifiant de façon unique chaque article issu de PubMed.
Enfin, certains billets de blogs spécialisés, des posters de recherches accompagnés de quelques échanges téléphoniques et en visioconférence nous ont permis d’arriver à un corpus de données conséquent :
450 résultats de recherche PubMed au 2 mars 2021,
131 documents retenus au 25 mai 2021,
dont 33 issus directement des recherches PubMed et 98 des documents sources,
dont 58 en simple citation dans la première partie “Rappels théoriques”,
Nous avons choisi de baser la sélection des articles sur le SCImago Journal Rank. En effet, le SJR et le facteur d’impact FI d’une revue (ou Impact Factor, IF) utilisent deux bases de données bibliographiques différentes pour leur calcul :
le SJR est calculé à partir de la base de données transdisciplinaire Scopus – détenue par Elsevier B.V. – qui indexe plus de 34.000 revues scientifiques toutes disciplines confondues incluant les sciences humaines et sociales ;
le FI est calculé à partir de la plateforme d’information scientifique Web of Science – détenue par Clarivate Analytics, ex. Thomson Reuters – qui indexe plus de 21.000 revues toutes disciplines confondues incluant les sciences humaines et sociales.
Le mode de calcul est différent :
le SJR est calculé pour une période de citation de 3 ans. Il tient compte de la notoriété des revues citantes. Il inclut de façon limitée les autocitations d’une revue ;
le FI est calculé pour une période de citation de 2 ans. Il ne tient pas compte de la notoriété des revues citantes. Il inclut toutes les autocitations d’une revue.
SCImago, (s.d.). SJR — SCImago Journal & Country Rank. En ligne. www.scimagojr.com (consulté le 7 juillet 2021)
Ainsi, les revues citées dans ce mémoire ont un indicateur SJR allant de 0,139 à 2,058, et un minimum de 0,6 pour les articles présentant une étude clinique. Ce filtre garantit la réputation des revues à relecture, mais ne prédit en aucun cas la confiance qu’on pourra accorder aux résultats présentés dans les études ; seule leur analyse qualitative pourra permettre de conclure. La liste des revues scientifiques citées dans la deuxième partie est fournie en annexe 1.
Pour terminer cet avant-propos et avant d’aborder le fond de la rédaction, nous citons le modèle de document, écrit dans le langage Markdown et formaté en \(\LaTeX\).
Afin d’introduire le contexte et le sujet de recherche développés dans ce mémoire, nous allons présenter le plan des chapitres qui répond aux questions du sous-titre. Les deux premières questions vont permettre de situer l’étude dans la littérature actuelle ; les deux questions suivantes aboutiront à la confrontation d’études cliniques.
1.1 Contexte
L’altération des fonctions auditives du malentendant provoque en premier lieu une gêne sociale. La recherche d’une meilleure compréhension de la parole en présence de bruit est un motif majeur de consultation médicale en spécialité O.R.L. en 2018 (JNA-IFOP, 2018)2. Cette démarche est parfois initiée par le patient qui souffre de déficit auditif et souvent par son entourage.
Des mécanismes physiologiques entrent en jeu lorsque le système auditif perçoit un signal bruité. Le démasquage binaural ainsi que l’analyse des indices fréquentiels et de la modulation d’enveloppe interviennent dans ce processus. Le but de l’amélioration du rapport signal sur bruit est de réduire la gêne du patient et de favoriser la perception vocale dans toutes les situations d’écoute.
Depuis la réglementation de 2018, qui a permis d’aboutir à la réforme du 100% Santé, la “dégradation significative de l’intelligibilité en présence de bruit” est devenue une condition suffisante pour appareiller.
L’audioprothésiste, dont le rôle est de garantir un fonctionnement optimal de l’appareillage, a à sa disposition trois leviers qui permettent l’amélioration du RSB : les algorithmes de réduction de bruit, la directivité microphonique et la compression dynamique. Si chaque paramètre a déjà fait l’objet de nombreuses recherches universitaires, nous nous intéressons ici au résultat de ces traitements et à la quantification de leur impact sur le RSB.
Lors du choix prothétique ou du contrôle d’efficacité, l’évaluation des performances dans le bruit des aides auditives fait appel à des notions objectives (traitement du signal) et subjectives (expérience du patient). En effet, la réhabilitation auditive touche aujourd’hui en grande partie à la connaissance du filtrage numérique, en plus des notions somatiques et psychoacoustiques.
1.2 Sujet de recherche
La comparaison des performances dans le bruit des aides auditives entre elles – ou selon leurs réglages – passe par une appréciation des effets qu’elles produisent. Ces effets peuvent être observés via des métriques cliniques (sur le patient) ou techniques (sur l’appareil). Dans les deux cas, des expériences in situ ont permis de quantifier les bénéfices de l’amélioration du RSB. La littérature scientifique propose également de rechercher des corrélations entre ces variables. Il est aujourd’hui clairement montré que la réduction du bruit n’est pas directement corrélée à l’amélioration de l’intelligibilité dans le bruit, mais à l’effort d’écoute. Nous verrons que l’accès à un traitement cognitif (ou intégration) plus rapide peut expliquer ce phénomène.
Dans le souci d’une exploitation complète de la dynamique auditive résiduelle du malentendant, l’audioprothésiste applique une compression, d’autant plus rapide qu’il souhaite protéger l’oreille des bruits impulsionnels. Cette compression dynamique va avoir deux effets contre-productifs : réduire le RSB lorsqu’il est positif et l’améliorer lorsqu’il est négatif. Le nivelage du contraste sonore ainsi créé apparaît encore plus prégnant après application des algorithmes de réduction du bruit et il conduit à une perte du gain sur le signal dans certaines conditions de bruit.
Dès lors, comment trouver l’équilibre entre la compression forte et rapide pour favoriser l’intelligibilité et un RSB favorable pour minimiser l’effort d’écoute ? Corréler la vitesse de compression au RSB, analysé de manière continue, semble être la meilleure alternative.
Nous conserverons ce fil rouge en tête pendant notre écriture :
\(\rightarrow\)Lister, décrire et caractériser les méthodes d’évaluation des performances dans le bruit des aides auditives.
2 Les raisons d’améliorer le RSB
2.1 Rappels d’audiologie
Même si l’étude est technique, il est nécessaire de préciser que l’audioprothésiste appareille des cerveaux auditifs. Nous allons donc rappeler les notions complémentaires de perception (périphérique) et de cognition (centrale) dans le processus d’intelligibilité, qu’il faudra définir. Cela permettra d’expliquer “Pourquoi ?” nous cherchons à améliorer le RSB.
2.1.1 Le système auditif périphérique
Le mécanisme passif de l’audition
L’organe de Corti est le véritable siège du mécanisme d’audition, à l’instar de la cochlée qui le contient. Il repose sur la membrane basilaire. On y trouve les cellules ciliées internes (environ 3500) qui réagissent de façon passive aux stimuli vibratoires de diverses fréquences et génèrent les potentiels d’action qui se propagent dans le nerf auditif. Elles assurent ainsi la transduction de l’énergie mécanique en énergie électrique. La répartition des CCI est liée à la rigidité progressive de la membrane basilaire face à l’onde sonore:
à la base, les sons aigus, peu énergiques, de faible longueur d’onde : \(\lambda = c/f = 20\sqrt{T}/f = 2cm\) pour 17kHz à 15°C
à l’apex, les sons graves, plus énergiques, de grande longueur d’onde : \(\lambda = 10m\) pour 34Hz à 15°C
Il s’agit de la tonotopie, découverte par Békésy dans les années 1950 sur des cochlées mortes.
Le mécanisme actif de la compréhension dans le bruit
La découverte des CCI sera jugée insuffisante pour expliquer l’excellente sélectivité fréquentielle de l’oreille. Il faudra attendre Johnstone et Boyle dans les années 1960 pour connaître les cellules ciliées externes (environ 12500) et comprendre leur rôle actif. En effet, le mécanisme d’amplification en bandes de fréquence étroites est lié à un message efférent déclenché par leur contraction rapide. Cette électromotilité peut atteindre une fréquence très élevée, de l’ordre de 20kHz.
La presbyacousie est définie comme une somme de phénomènes liés au vieillissement. Elle est :
mécanique lorsque les osselets, qui jouent le rôle d’amplificateur, perdent cette capacité,
sensorielle lorsque les CCI sont endommagées, provoquant un abaissement du seuil tonal,
nerveuse lorsque les fibres démyélinisées réduisent la propagation des potentiels d’action,
métabolique lorsque les vaisseaux de l’organe de Corti deviennent moins bien irrigués en oxygène.
Il en découle des pathologies diverses. Tout d’abord sur la capacité à distinguer le spectre du signal : il s’agit d’une atteinte du codage fréquentiel. Des courbes d’accord neurales (PTC, Psychophysical Tuning Curves) élargies sont le signe d’une perte d’acuité dans la différenciation des fréquences qui composent le signal de parole. Ainsi, la perte de sélectivité fréquentielle mène à une perte d’information dans le signal utile (Preminger & Wiley, 1985). Ensuite, un délai de traitement est introduit par le manque d’indices spectraux. Les malentendants éprouvent donc plus de difficultés à détecter la parole ce qui se traduit par une élévation des seuils de détection (Schijndel et al., 2001).
Par ailleurs, il a été démontré que la distorsion des sons de haute fréquence affecte le spectre de la parole et réduit l’intelligibilité. Ce même phénomène est à l’œuvre dans le cas du vieillissement des voies auditives supérieures, ce qui conduit à un élargissement des filtres auditifs (Lorenzi et al., 2006; MacDonald et al., 2010).
Si l’exploitation de la structure temporelle fine devient médiocre dans le cas d’une perte auditive endo-cochléaire moyenne (Hopkins & Moore, 2007), ce n’est pas pour autant que les seuils audiométriques se trouvent élevés (Hopkins & Moore, 2011). C’est ainsi qu’on parle de surdité cachée. Un travail récent en pré-print (Garrett et al., 2020) semble confirmer le rôle de la synaptopathie cochléaire dans la détérioration de l’intelligibilité dans le bruit.
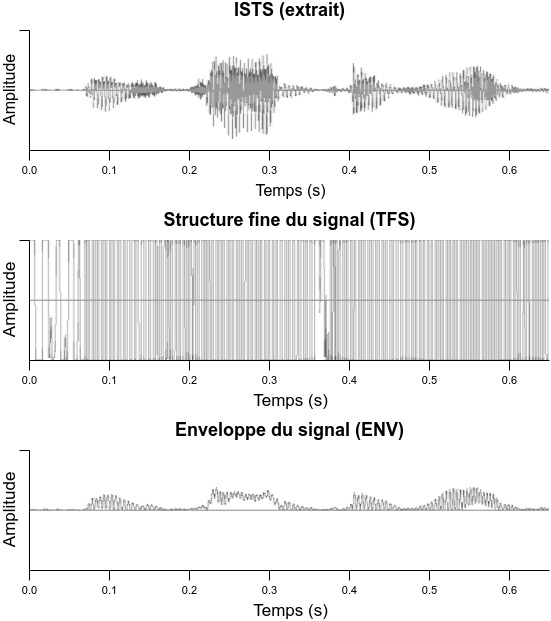
Figure 1: Enveloppe et structure fine d’une forme d’onde extraite de l’ISTS
Deuxième source d’information mise en évidence dans la figure 1, le codage en intensité apporte des indices supplémentaires pour la reconnaissance de la parole. Un déficit de codage, qu’il soit fréquentiel ou en intensité, conduit à une réduction de la capacité à discerner des événements sonores distincts (Paquier, 2013). Le bruit apporte des fluctuations aléatoires dans la modulation d’amplitude et diminue le contraste entre les crêtes et les vallées de la parole (Dubbelboer & Houtgast, 2007). Pour un même seuil d’intelligibilité, le malentendant a besoin d’un meilleur RSB par rapport au normo-entendant (Plomp, 1994).
Là aussi, la synaptopathie, lorsqu’elle est issue d’une lésion cochléaire due à une exposition au bruit, conduit à une moins bonne exploitation des crêtes de la parole (Paul et al., 2017). La forme de l’enveloppe a une telle importance dans le processus d’intelligibilité qu’un indice d’altération (EDI, Envelope Difference Index) a été développé (Fortune et al., 1994).
Le principal outil dont se sert le cortex auditif pour percevoir la parole dans le bruit est le démasquage binaural. La perception des infimes différences de niveau (ILD, Interaural Level Difference) et de temps (ITD, Interaural Time Difference) entre les deux oreilles sont des indices sur la localisation et la nature de la parole au milieu bruyant. Or, il s’avère que les lésions cochléaires dégradent la capacité à repérer les différences de phase (Lacher-Fougère & Demany, 2005), ce qui fait appel aux deux notions. D’après la littérature, il est clair que la séparation des sources de parole et de bruit permet d’améliorer l’intelligibilité (Lavandier & Culling, 2008). De la même manière, si la parole et le bruit masquant sont diffusés face au sujet, on empêche le démasquage binaural d’opérer (Marrone et al., 2008). L’appareillage stéréophonique contribue à restaurer des fonctions physiologiques déficientes.
2.1.2 La phonétique acoustique
La transmission du message vocal, et surtout de notre point de vue, sa réception via l’audition, fait appel à plusieurs niveaux perceptifs. On distinguera deux types de perception, en fonction de ce qui est à évaluer :
la discrimination : capacité à discerner les phonèmes les uns des autres,
l’intelligibilité : “degré de compréhension d’un message verbal ou d’une forme de parole (naturelle ou synthétisée), déterminé à l’aide de tests de perception”, d’après la définition du Larousse.
La présence de bruit vient déséquilibrer le processus de reconnaissance de la parole sur ces deux niveaux. Ce bruit peut prendre la forme d’une perturbation purement acoustique – on parle de masquage énergétique – ou d’une perturbation linguistique – on parle de masquage informationnel – (Brungart et al., 2001). Ainsi, il a été prouvé dans les années 1990 que la parole interférente et surtout le bruit fluctuant peuvent modifier le seuil d’intelligibilité (Festen & Plomp, 1990). Cela montre que les difficultés de compréhension en présence de bruit pour les malentendants bénéficient d’un socle de littérature important.
De plus, on sait maintenant que le système auditif décompose le spectre de la parole émise par le locuteur pour identifier les phonèmes ; c’est ce qu’a montré une étude reposant sur l’analyse de la phase du signal pour l’identification des consonnes (Buss et al., 2004). L’utilisation des consonnes dans cette étude était justifiée par leur forte valeur informationnelle. En effet, la plupart des indices de compréhension y résident.
Enfin, la banane vocale, utilisée en phonétique pour représenter la répartition énergétique des phonèmes, nous permet de percevoir l’impact d’un bruit stationnaire sur les différents formants des consonnes voisées et des voyelles ainsi que sur les plosives. Rappelons que, mécaniquement, un son grave est plus masquant qu’un son aigu à même niveau de pression acoustique. Par conséquent, le masquage énergétique par les basses fréquences est très efficace et il convient de le limiter pour améliorer l’intelligibilité.
2.1.3 La capacité cognitive
Puisque le déclin auditif engendre un déclin cognitif, il est aujourd’hui recommandé aux professionnels de l’audition d’inclure des facteurs de santé mentale dans leur pratique clinique (Pichora-Fuller, 2015). La perte de RSB moyenne évolue progressivement par décade dans la population générale à partir de 20 ans, d’après une thèse doctorale de médecine sur la normalité de l’audition dans le bruit par classe d’âges (Decambron, 2018). Les environnements bruyants deviennent de plus en plus difficiles à supporter avec l’âge, et on observe un isolement social autoentretenu par la perte auditive et par l’accélération du déclin cognitif. La qualité de vie des patients malentendants non appareillés ayant une perte moyenne à profonde décroît rapidement (Fortunato et al., 2016).
Des modèles cognitifs théoriques sont développés afin d’évaluer les processus corticaux à l’œuvre pendant l’éveil. Un principe se dégage de ces études : les ressources mentales sont limitées. Ainsi, une tâche complexe – comme la compréhension de la parole dans le bruit – sera bridée par la mémoire de travail globale du sujet (Wingfield, 2016). Les informations perceptuelles, auditives notamment, ne sont pas toutes traitées au niveau supérieur, et le rôle de la mémoire de travail est de mettre ces informations en attente pour les traiter quelques instants plus tard. Cela expliquerait en partie l’influence de l’âge sur la capacité à comprendre la parole en présence de bruit, car la capacité à différencier des indices temporels est diminuée (Černý et al., 2018). Chez les malentendants, l’association automatique entre l’information phonologique et les représentations langagières stockées dans la mémoire à long terme est ralentie, d’autant plus en présence de bruit (Carroll et al., 2016).
La réduction du bruit par les appareils auditifs ainsi que leur amélioration du RSB peut permettre de réduire les effets du bruit, mais seulement si les sujets ont conservé une bonne mémoire de travail. C’est bien la réduction du délai de compréhension qui permet un stockage plus efficace par la mémoire de travail (Ng et al., 2013). De fait, les patients appareillés voient leurs capacités cognitives conservées grâce à l’entraînement auditif, à l’inverse du processus de déclin cité précédemment.
Le réglage du traitement de la dynamique par les processeurs de son (cf. compression chapitre suivant) engendre quant à lui des effets opposés selon le type de mémoire de travail :
une compression rapide – priorité au phonème – procure de meilleurs scores d’intelligibilité chez les sujets à forte mémoire de travail,
une compression lente – priorité à l’enveloppe – procure de meilleurs scores d’intelligibilité chez les sujets à faible mémoire de travail.
Pendant le processus d’appareillage, il faut se remémorer que le profil cognitif du patient agit directement sur la capacité de compréhension au milieu d’un bruit fluctuant (Ohlenforst et al., 2016).
2.2 L’intelligibilité dans le bruit
Dans leur pratique quotidienne de l’audioprothèse, les professionnels sont amenés à mesurer le seuil d’intelligibilité du patient “oreilles nues” puis de le comparer au seuil “appareillé”. Le maintien de ce gain prothétique vocal est à la base du processus d’appareillage.
2.2.1 L’audiométrie vocale dans le bruit
La publication récente des “recommandations de la Société Française d’Audiologie et de la Société Française d’ORL et de chirurgie cervico-faciale pour la pratique de l’audiométrie vocale dans le bruit chez l’adulte” (SFA, 2020) représente une ressource commune multidisciplinaire. L’audiométrie vocale dans le bruit permet, au-delà de la recherche des seuils tonaux et vocaux de perception, de prendre en compte la fonction auditive dans son intégralité et de façon écologique. De ce fait, elle peut également servir au dépistage de troubles auditifs, avant un diagnostic complet ultérieur, lors d’un bilan auditif central. Une procédure d’AVB est caractérisée par plusieurs paramètres :
Matériel vocal : format (logatomes, mots, phrases, etc.), support (CD, matrice, etc.) et calibration du message vocal à reconnaître.
Bruit masquant : type de bruit (bruit blanc, bruit vocal, filtré ou non, etc.) utilisé pour simuler les conditions réelles.
Disposition : nombre de haut-parleurs et répartition autour du patient.
Déroulement : test adaptatif, listes d’entraînement, unité d’erreur (le phonème, le mot, etc.) et prise en compte du traitement du signal (réduction du bruit, directivité, compression, etc.).
L’audiométrie vocale dans le bruit en français est pratiquée sur la base de procédures publiées. Voici les plus courantes :
L’Audiométrie Verbo-fréquentielle, AVfB, développée par M. Léon Dodelé (Collège national d’audioprothèse (France), 2007). Chacune des 5 listes est composée de 18 logatomes. Elles sont diffusées en champ-libre, en face du patient, à 0°. Le bruit d’Onde Vocale Globale OVG est constitué par un mélange de paroles issues de deux couples mixtes, l’un parlant anglais et l’autre français. Il est diffusé à l’arrière du patient, à 180°. Valeur normative en dB RSB : 100% si >3
Le HINT, originellement développé en anglais (Nilsson et al., 1994), a été adapté en français (Vaillancourt et al., 2005). Ce test contient 12 listes de 20 phrases. Un bruit blanc fixé à 65dBSPL, filtré selon le spectre des listes, est diffusé alternativement en face, à gauche puis à droite du patient. Le niveau de RSB est adaptatif par pas de 4dB puis de 2dB sur les 16 dernières phrases. Valeur normative en dB RSB : moyenne −7,2 ; robustesse : 0,8
Le French Intelligibility Sentence Test, FIST, est issu du HINT(Luts et al., 2008). Sur un bruit blanc filtré, fixé à 65dBSPL, le RSB est adapté par pas de 2dB en fonction des réponses du patient. Quatorze listes de 10 phrases pré-enregistrées sont utilisées. Ce test est réalisé au casque. Valeur normative en dB RSB : moyenne −7,4 ; robustesse : 0,7
La Vocale Rapide dans le Bruit, VRB, a été conçue au CHRU de Lille (Leclercq & Renard, 2014). Le niveau de parole est fixe et le RSB est adapté par pas de 3dB entre +18dB et −3dB. Le test contient 15 listes de 9 phrases. Il est réalisé préférentiellement en champ-libre sur 5 haut-parleurs. Valeur normative en dB RSB : moyenne −0,08 ; robustesse : 0,55
Le FraMatrix est l’adaptation du Matrix, validé en français (Jansen et al., 2012). Le matériel vocal aléatoire est issu d’une matrice de 50 mots : 10 prénoms, 10 verbes, 10 nombres, 10 objets, 10 couleurs. Le bruit fixé à 65dBSPL est issu de la concaténation des phrases disponibles. Deux haut-parleurs sont placés face au patient, l’un pour le signal, l’autre pour le bruit. La procédure est adaptative, le niveau de la parole variant finement autour du seuil ; le RSB alterne entre favorable et défavorable à chaque fois que le patient identifie ou non la moitié des mots de la phrase. Valeur normative en dB RSB : moyenne −6 ; robustesse : 1
On perçoit ici l’hétérogénéité des procédures, à la fois dans le matériel vocal, dans le bruit et dans le format de passation. Chaque test ayant son intérêt – en dépistage, en diagnostic, en audioprothèse, en étude clinique – il nous semble pertinent de conserver des paramètres identiques tout au long de la mesure afin de comparer la variation du RSB.
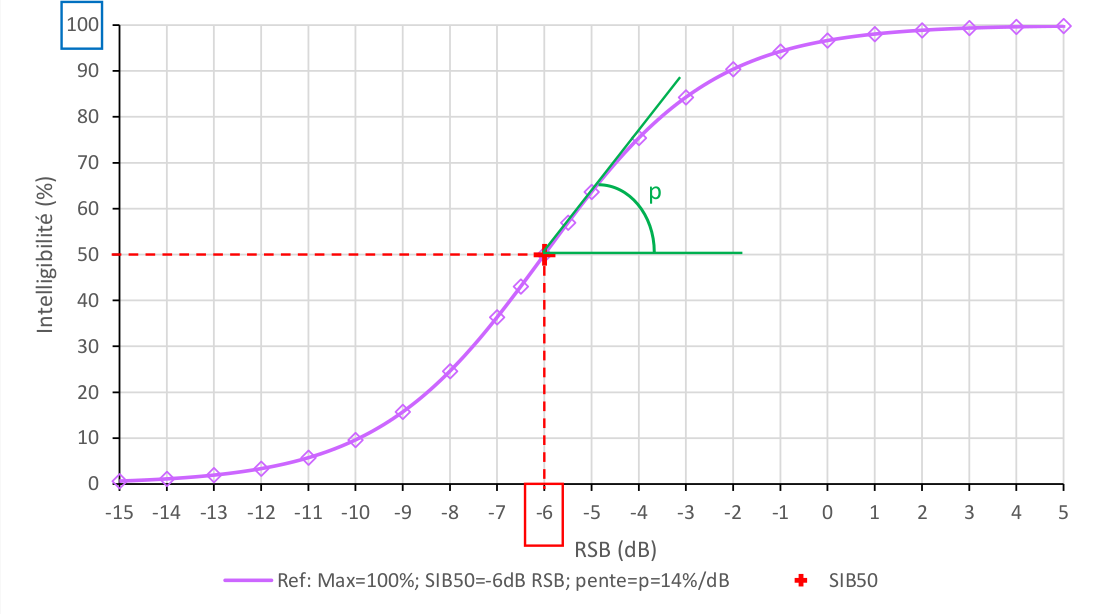
Figure 2: Exemple de fonction d’intelligibilité avec un maximum d’intelligibilité de 100\% ; un SIB50 = −6dB RSB et une pente p = 14\%/dB – SFA, 2020
Il sera fait mention dans ce mémoire de tests utilisant un pourcentage d’intelligibilité, tels que le Connected Speech Test, CST ou le Speech Perception In Noise Test, SPIN. Mais la majorité des résultats sont présentés sous la forme d’un Speech Reception Threshold à 50%, SRT50, ou Seuil d’Intelligibilité dans le Bruit, SIB50, représentant un score de 50% d’intelligibilité pour un certain RSB. Lorsque les concepteurs d’études recherchent un autre seuil, ils le précisent : SIB80 pour un score de 80% d’intelligibilité.
2.2.2 La réglementation
L’Arrêté du 14 novembre 2018 “portant modification des modalités de prise en charge des aides auditives […]” est le socle législatif de la loi “100% Santé” qui est entrée pleinement en vigueur le 1er janvier 2021. Le texte étend l’appareillage pour les patients présentant un décalage du seuil d’intelligibilité dans le bruit d’au moins 3dB par rapport à la référence normative du test utilisé. Il y est écrit :
“dégradation significative de l’intelligibilité en présence de bruit, définie par un écart du rapport signal de parole / niveau de bruit (RSB en dB) de plus de 3dB par rapport à la norme.”
C’est la raison pour laquelle il faut savoir apprécier la robustesse d’une épreuve vocale dans le bruit. L’écart-type permet de statuer sur la véracité du score.
Par exemple : un score de −1,6dB de RSB pour le SIB50 lors d’un test au FraMatrix est bien conforme à la prescription d’appareillage. En effet, la référence normative de ce test est de −6dB, soit un écart 4,4dB, ce qui est bien supérieur à 3dB de perte, même en prenant en compte l’écart-type de ±1dB.
3 Les méthodes pour améliorer le RSB
Intéressons-nous maintenant aux technologies développées par les fabricants d’aides auditives pour améliorer le RSB au niveau de la sortie de leurs appareils. Il s’agit de répondre à la question “Comment ?” améliorer le RSB.
3.1 La réduction du bruit
Le bruit dont il est question dans notre étude est celui de la définition n°6 (rubrique télécommunication) du Larousse : “Ensemble de perturbations de toute nature et de toute origine venant se superposer à un signal utile en un point quelconque de l’espace ou d’une voie de transmission”. Le rapport signal sur bruit, RSB, est le rapport des puissances acoustiques P (en W) – ou des pressions acoustiques p (en Pa) au carré – du signal S et du bruit B, équivalent à la différence algébrique entre les niveaux de pression N (en dB). (La référence p0 n’intervient pas.) \[RSB = 10 log_{10} \left( \cfrac{p^2_S}{ p^2_B} \right) = 20 log_{10} \left( \cfrac{p_S}{p_B} \right) = 20log_{10} (p_S) - 20log_{10} (p_B) = N_S - N_B\ \text{(en dB)}\](1) Le signal utile, celui de la parole, comporte des caractéristiques phonétiques instantanées abordées dans le chapitre précédent. À long terme, il possède un spectre très reconnaissable. Le signal vocal international de test, International Speech Test Signal, ISTS, a été créé dans le but de représenter statistiquement ce spectre (Holube et al., 2010). Le bruit comporte lui des caractéristiques beaucoup plus diverses : fluctuant, stationnaire, impulsionnel, etc. Chaque type de bruit peut être traité de façon adaptée.
Réducteur de bruit impulsionnel pour atténuer les pics de pression de l’ordre de 10ms.
Réducteur de bruit de vent qui pourra supprimer les variations interaurales de basse fréquence, typiques de l’impact des masses d’air sur les microphones (Chung, 2012). On notera qu’il est possible de limiter ce désagrément par l’utilisation de l’effet pavillonnaire naturel, grâce aux appareils intra-auriculaires et aux écouteurs déportés incluant un microphone.
Réducteur de bruit ambiant basé soit sur la directivité microphonique soit sur le filtrage spectral du signal bruité. Voyons pour commencer le fonctionnement de ce dernier.
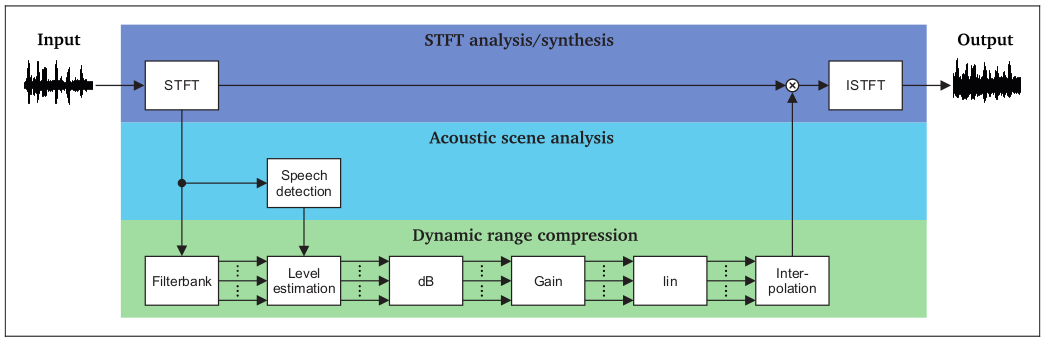
3.1.1 Le filtrage spectral
Les deux méthodes courantes sont basées sur l’analyse spectrale par transformée de Fourier (Fourier Transform, FT), décrite dans “Hearing Aids” (Dillon, 2012).
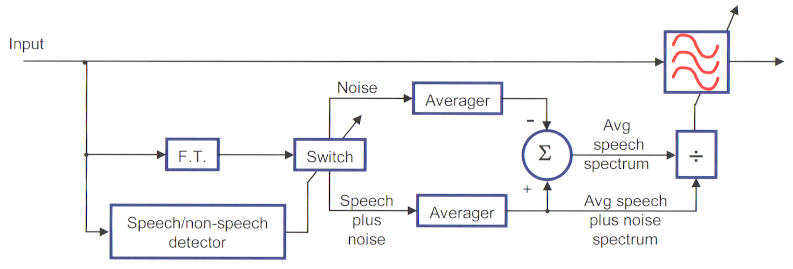
Le filtrage de Wiener repose sur l’analyse continue du RSB pour ajuster le gain en permanence. L’estimation du bruit est réalisée seulement pendant les périodes de pause de la parole (Speech/non-speech detector).
Figure 3: Schéma fonctionnel du filtrage de Wiener – Dillon, 2012
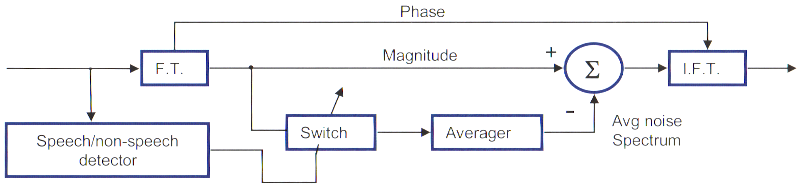
Quant à la méthode de soustraction spectrale, elle consiste à supprimer le spectre du bruit directement dans le spectre du signal bruité. Là encore, il faudra identifier le bruit pendant les périodes de pause de la parole. Pour revenir dans le domaine temporel, une transformée de Fourier inverse (Inverse Fourier Transform, IFT) sera appliquée, d’où la nécessité d’obtenir la phase du signal d’origine.
Figure 4: Schéma fonctionnel de la soustraction spectrale – Dillon, 2012
Le signal peut, en premier lieu, être filtré numériquement par bande de fréquence. Le gain adaptatif est alors corrélé à la modulation du signal, représentative de la présence de parole dans chaque bande de fréquence considérée. Cependant, à l’issu de ces filtrages spectraux efficaces sur le bruit ambiant, on introduit une distorsion qui perturbe la compréhension de la parole. C’est pourquoi des approches hybrides sont étudiées.
3.1.2 L’intelligence artificielle
L’idée d’utiliser des processus automatisés pour la suppression du bruit est ancienne, mais c’est seulement depuis que les ressources informatiques sont suffisantes, à la fois en calcul et en stockage, que des mises en œuvre ont vu le jour.
Il existe deux niveaux d’approche de l’intelligence artificielle.
L’apprentissage automatique, ou machine-learning correspond à l’utilisation de données d’entraînement structurées pour les appliquer à de nouvelles données. En fournissant un ensemble d’enregistrements de signaux sources, associés à une version modifiée de chaque signal, l’algorithme est capable de générer un nouveau signal modifié, à partir d’une source inconnue. De nombreux usages sont possibles sur des données sonores :
En musique, c’est le cas du projet de ressources ouvertes pour la séparation des sources musicales SigSep(Rafii et al., 2018). Les données pré-entraînées (training dataset) sont des stems qui regroupent différents instruments. spleeter3, développé par Deezer Research (Hennequin et al., 2020) et issu du même projet, est une application qui offre la possibilité de séparer les pistes instrumentales de n’importe quel morceau musical.
En musique toujours, l’apprentissage automatique est utilisé pour classifier les morceaux par genre musical, préalablement défini.
En audiologie, des travaux sont en cours pour réaliser une audiométrie adaptative en ligne, pilotée par l’apprentissage automatique des courbes tonales (Barbour et al., 2019).
L’apprentissage profond, ou deep-learning, repose sur les mêmes outils statistiques, mais ne nécessite pas de données structurées. Chaque couche d’un réseau neuronal artificiel est en charge d’informer de façon récursive les adaptations à réaliser sur la couche précédente afin d’obtenir le meilleur résultat possible sur la couche de sortie. Ce processus est appelé un Réseau de Neurones Récurrents, RNR, ou Recurrent Neural Network, RNN. Son utilisation devient de plus en plus commune :
Utilisation hybride d’un processeur de son standard à filtrage spectral, adossé à un RNR qui réalise la détection de la présence de voix. (Valin, 2018).
Figure 5: Schéma fonctionnel du filtrage spectral contrôlé par RNR – Valin, 2018
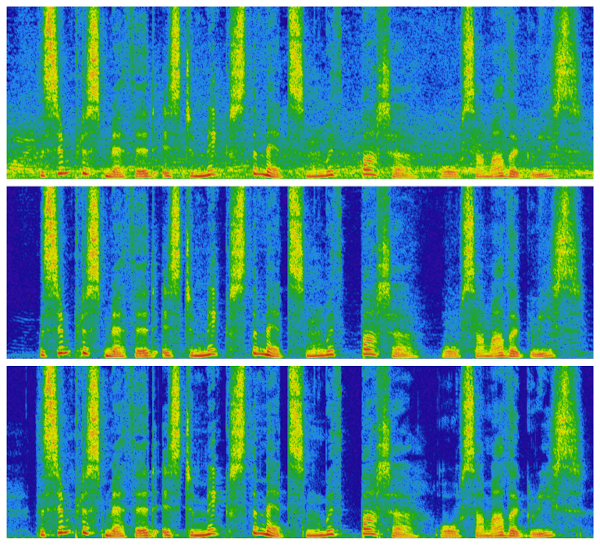
Les résultats sont nettement meilleurs sur le RSB en sortie qu’avec une méthode traditionnelle, surtout sur les bruits non stationnaires. L’implémentation logicielle RNNoise4 est utilisée pour apprécier très finement le gain à appliquer par bande. Elle est également développée par Jean-Marc Valin, Mozilla Corporation.
Figure 6: Exemple de suppression d’un bruit de babil à +15dB de RSB. Spectrogramme de parole bruitée (en haut), débruitée (au milieu), et originale (en bas). Par souci de clareté, seule la bande 0-12kHz est affichée – Valin, 2018
Utilisation d’un réseau de neurones récurrents profond pour la suppression du bruit de vent (Keshavarzi et al., 2018). Le masque idéal est déterminé par l’entraînement du RNR à “reconnaître” la parole bruitée via un apprentissage automatique supervisé. Parmi les trois conditions testées – sans traitement, avec RNR, et avec filtre passe-haut – les sujets testés ont préféré l’approche deep learning, ce que confirme l’analyse du RSB.
Les auteurs précisent qu’il devrait être possible de désactiver automatiquement le masquage en l’absence de vent. Grâce aux capacités d’autoadaptation du RNR, de futurs travaux pourraient montrer comment le généraliser à des locuteurs ne faisant pas partie des données d’entraînement.
La réduction par codage parcimonieux, ou Sparse Coding Shrinkage, est une technique de réduction du bruit issue du secteur de l’image. Également basée sur un réseau neuronal, elle permet la reconstruction du signal à partir de quelques projections linéaires. Son application à la réduction du bruit sonore a montré de meilleurs résultats subjectifs qu’un filtrage de Wiener traditionnel (Sang et al., 2015).
Il existe sans doute d’autres mises en œuvre de cette technologie. La difficulté reste encore d’embarquer les données d’entraînement et les ressources de calcul instantané dans une aide auditive.
3.2 La directivité adaptative
Le mode de directivité microphonique d’une aide auditive offre un accés mécanique à l’amélioration du RSB, sans avoir recours au traitement du signal.
Un microphone seul est caractérisé par sa directivité. Il est dit omnidirectionnel s’il capte les variations de pression acoustique tout autour de lui ou cardioïde s’il capte davantage à l’avant qu’à l’arrière ; son diagramme polaire représente alors une forme de cœur. Cette propriété est intrinsèque à la technologie utilisée et la sensibilité, en fonction de l’angle d’incidence, est fixe.
Toutefois, l’utilisation conjointe de 2 microphones omnidirectionnels permet d’accéder à un digramme polaire variable. Dans des conditions idéales, le microphone avant capte à la fois la parole et le bruit ambiant légèrement en avance sur le microphone arrière. L’ajout d’un décalage temporel T = a/c, avec a la distance entre les microphones et c la célérité du son, aboutit à la création d’une cardioïde, donc d’une directivité fixe.
Imaginons maintenant qu’on ajuste le décalage temporel en minimisant, par le calcul, un coefficient de rétroaction directement lié à l’angle d’incidence de la source ; on obtient une directivité de l’ensemble modulable en temps réel : c’est la directivité adaptative.
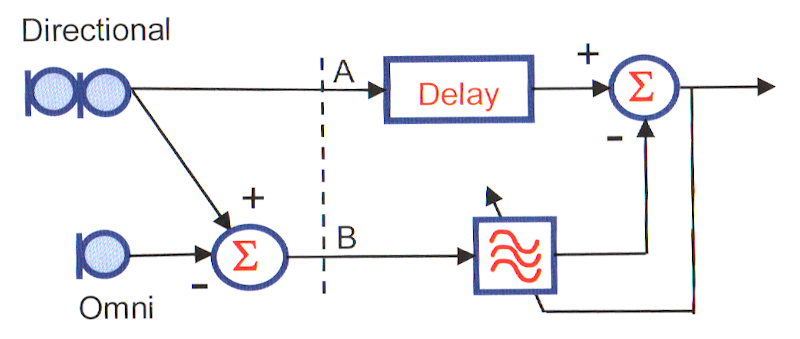
Figure 7: Schéma fonctionnel d’un réducteur de bruit adaptatif – Dillon, 2012
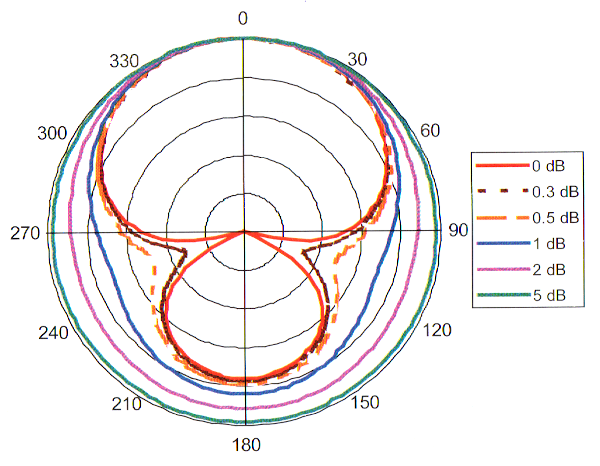
Le parfait équilibre en sensibilité directionnelle entre les deux microphones semble jouer un rôle important dans la stabilité du système. On voit sur la figure 8 qu’un léger déséquilibre dans leurs courbes de réponse suffit à faire disparaître l’atténuation complète à 110°, propre à l’hypercardioïde. Malgré tout, cette faiblesse est jugée utile pour créer des transitions douces entre les modes microphoniques.
Figure 8: Variation du diagramme polaire pour plusieurs niveaux de déséquilibre en sensibilité entre les microphones. Les cercles concentriques diffèrent de 5dB en sensibilité – Dillon 2012
En terme de performance, la directivité fixe ou adaptative apporte globalement de meilleurs résultats que la directivité omnidirectionnelle dans les deux cas suivants :
Amélioration du RSB : la directivité fixe est depuis longtemps reconnue comme étant plus performante sur l’amélioration du RSB que la directivité omnidirectionnelle. On a constaté jusqu’à 7dB d’écart pour les aides auditives à double microphones (Bilsen et al., 1993; Valente et al., 1995).
Amélioration du SIB50 : les résultats aux tests vocaux dans le bruit sont sensiblement améliorés grâce aux systèmes directionnels à double microphones associés à un filtrage en fréquence, que ce soit pour les BTE ou les ITE (Pumford et al., 2000). Il est recommandé d’associer la directivité adaptative à un traitement adaptatif de la compression pour des résultats encore meilleurs lorsque le bruit et la parole proviennent de directions différentes (Blamey et al., 2006).
Les limites de la performance de la directivité fixe ou adaptative sont également connues :
Préférence individuelle : si les améliorations objectives sont évidentes, les variations individuelles dans des conditions réelles conduisent les auteurs d’études à beaucoup plus de prudence. Ainsi, les questionnaires d’évaluation n’ont pas montré d’avantage significatif à la directivité (Gnewikow et al., 2009). Des facteurs propres au sujet et à son environnement ont été mis en cause : la présence d’indices visuels, le niveau de RSB, la configuration du bruit, la taille de l’évent ou la réverbération (Park et al., 2015).
Conditions environnementales : dans une situation fortement réverbérante, la formation de faisceau n’est plus suffisante pour assurer l’annulation de l’onde arrière (Greenberg & Zurek, 1992). Par ailleurs, une étude a montré que les utilisateurs optent eux-mêmes pour un réglage omnidirectionnel les \(\scriptstyle 3/4\) du temps. Si l’utilisation d’une directivité microphonique offre de sérieux avantages lorsque la source se trouve à l’avant, de façon nettement séparée du bruit, ces conditions ne se rencontrent pas si souvent dans la vie quotidienne (Cord et al., 2002).
L’effet de la directivité microphonique est d’autant plus grand si l’adaptation est réalisée de façon binaurale et symétrique. Une étude a testé l’impact d’un réglage asymétrique : bien que la paire omnidirectionnel/adaptatif procure de meilleurs seuils d’intelligibilité SIB71 que la paire omni/omni, c’est toujours la symétrie apportée par la paire adapt./adapt. qui mène à des résultats optimaux (Mackenzie & Lutman, 2005).
Le développement plus récent de la communication binaurale sans-fil entre les aides auditives droite et gauche conduit au regroupement fonctionnel des 4 microphones. L’amélioration de l’intelligibilité est décrite comme restreinte mais existante, essentiellement chez les sujets présentant une plus forte perte auditive (Picou & Ricketts, 2019).
3.3 La compression
La perte auditive neurosensorielle, de type presbyacousie par exemple, induit une diminution de la dynamique perceptuelle ; les sons faibles sont difficilement perçus, à cause d’un seuil tonal abaissé, et les sons forts donnent rapidement une sensation de douleur. Ce phénomène physiologique, dû à la compensation de la perte auditive endo-cochléaire, est appelé le recrutement. Il peut être atténué par une amplification, qui va se charger d’augmenter les sons de niveau faible et moyen afin de restituer une forme d’audition résiduelle. On y adjoint une compression qui va se charger de limiter les sons forts afin de favoriser le confort auditif.
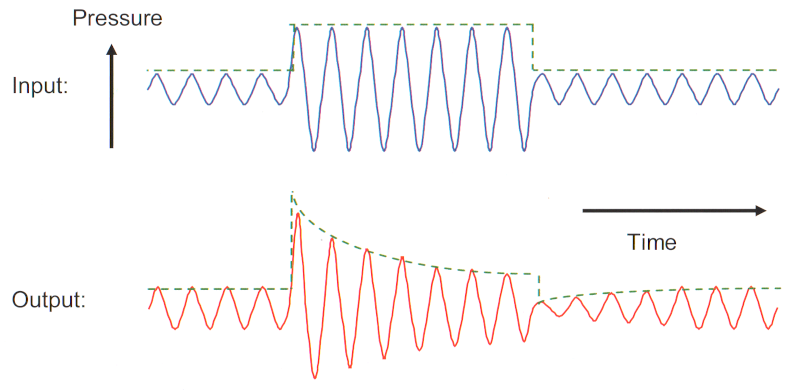
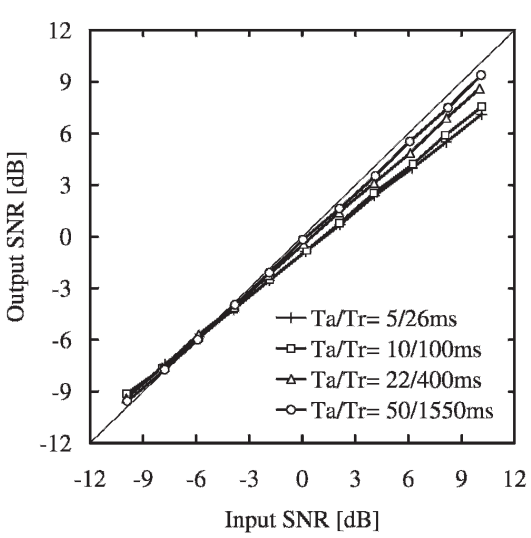
La compression est caractérisée par deux grandeurs temporelles de fonctionnement :
le temps d’attaque Ta qui représente la durée que le processus mettra à adapter le niveau d’intensité du signal en sortie,
le temps de retour Tr, durée nécessaire pour revenir à un état de repos.
Figure 9: Formes d’onde en entrée et en sortie de compresseur, montrant les transitions d’attaque et de retour qui suivent respectivement une augmentation et une diminution du niveau du signal. La ligne pointillée montre l’enveloppe de la moitié positive du signal – Dillon, 2012
Le but de la compression, outre l’optimisation de la dynamique résiduelle, consiste à augmenter le contraste inter-phonémique et à réduire les différences intra-phonémiques, et ainsi améliorer l’intelligibilité dans le calme. La gestion de ces constantes de temps aura donc une importance toute particulière sur le SIB50.
Par ailleurs, le confort auditif passe par la limitation du niveau de sortie en plafonnant le gain. Elle peut être réalisée à deux moments de la chaîne d’amplification :
soit en fonction du niveau d’entrée, Automatic Gain Control (input), AGCi,
soit en fonction du niveau de sortie, Automatic Gain Control (output), AGCo.
Ce dernier mode offre la possibilité d’amortir l’écrêtage du signal, sans quoi des distorsions apparaîtraient. On gère de façon douce la puissance maximum de sortie, on Maximum Power Output, MPO.
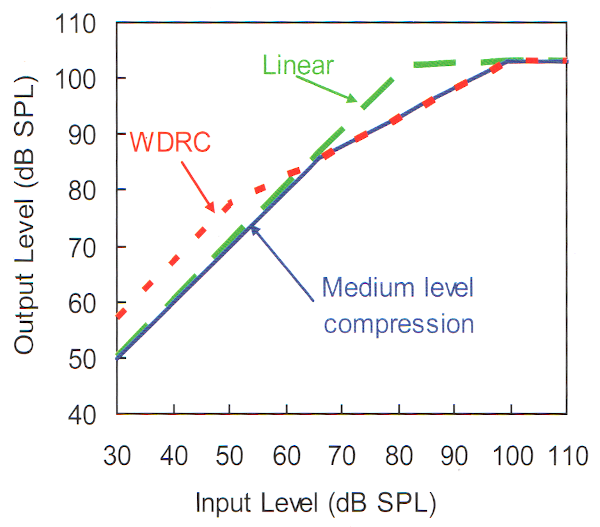
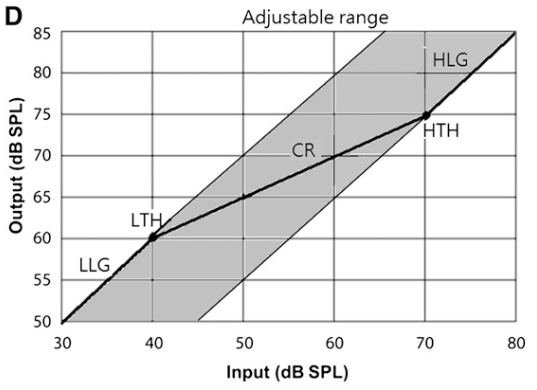
Le taux de compression (par exemple 2:1 si une variation de 2dB en entrée se traduit par une augmentation de 1dB en sortie) peut être progressif, sur l’intégralité de la plage dynamique en entrée (de faible à fort) : on la nomme alors Wide Dynamic Range Compression, WDRC. La figure 10 montre une première pente très tôt dans cette courbe, à l’inverse de la compression linéaire. À très faible niveau, on peut être amené à activer une expansion, c’est à dire un point d’enclenchement, ou Threshold Knee, TK, en-dessous duquel le taux est inférieur à 1:1, par exemple 1:2. Ce réglage se traduira par un gain nul sur les sons très faibles.
Figure 10: Courbes entrée/sortie d’une compression moyenne, d’une WDRC et d’une amplification linéaire, chacune combinée à une limitation du niveau de sortie par compression ou par écrêtage – Dillon, 2012
Pour compléter ces rappels de base sur la compression, rappelons que différents taux peuvent être appliqués sur plusieurs bandes de fréquence. En audioprothèse, il est fréquent de voir une compression faible sur les basses fréquences et une compression forte sur les hautes fréquences (Treble Increase at Low Levels, TILL), du fait que les pertes auditives sont généralement plus importantes dans les aigus. La sensation sonore, quantifiée en sonie, est normalisée dans chaque bande et le gain est adapté au niveau du signal d’entrée, évalué via deux méthodes, selon les technologies :
les compressions mono ou multi-canales, qui appliquent un gain en fonction du niveau d’entrée, mesuré dans la bande considérée (banque de filtres),
les systèmes Channel Free qui calculent les courbes de réponses à la volée, en fonction du niveau d’entrée, mesuré de façon globale (filtres FIR paramétrables).
Voyons maintenant, d’après la littérature, comment la compression peut agir sur le bruit, influer sur le RSB en sortie et impacter l’intelligibilité de la parole.
Distorsion d’enveloppe : puisque l’amplification linéaire augmente à la fois le signal et le bruit, le RSB reste inchangé. Mais on sait qu’un taux de compression trop élevé distord le signal et apporte une altération de l’enveloppe temporelle, ce qui réduit significativement l’intelligibiité (Jenstad & Souza, 2007).
Contraste d’enveloppe : pour des temps d’attaque et de retour rapides, la compression aura tendance à diminuer le RSB lorsqu’il est positif, et à l’augmenter lorsqu’il est négatif, réduisant ainsi le contraste de l’enveloppe temporelle. Ce comportement améliore le confort mais n’a pas d’effet significatif sur l’intelligibilité (Kates, 2010).
Nombre de canaux : l’augmentation du nombre de canaux de compression au-delà de deux n’est pas reconnue comme apportant un bénéfice formel. En revanche, la technologie Channel Free, abordée plus haut, présente un avantage jusqu’à 10dB de RSB supérieur sur la reconnaissance des consonnes, par rapport à la compression multi-canale (DeSilva et al., 2016). Nota bene: ne pas confondre avec le nombre de bandes de fréquence de réglages ; l’oreille possèdant 24 bandes critiques – filtres auditifs de largeur isosonique – il est inutile de normaliser la sonie sur plus de bandes. (cf. travaux de B.C. Moore, 1986, revue Audiology, non cotée SJR)
Vitesse de compression : les capacités cognitives limitent la faculté à exploiter les informations de structure fine. Dés lors, les paramètres temporels Ta et Tr sont à adapter en fonction du patient (Moore, 2008). En outre, un temps de retour trop court peut générer un effet de “pompage”, décrit comme étant une variation continue et perceptible du niveau de sortie due à l’adaptation permanente du gain (Souza, 2002).
Bruit de fonctionnement : l’expansion, ou taux de compression inférieur à 1, qu’elle soit appliquée à une compression mono ou multi-canale, présente l’avantage de supprimer le bruit électronique interne des appareils auditifs, tout en maintenant une bonne audibilité dans le calme (Zakis & Wise, 2007).
L’application de la compression dans la réduction du bruit est surtout adaptée aux bruits stationnaires de basse fréquence, dont le potentiel masquant est supérieur. Lorsque le bruit perturbant possède également un spectre de parole, il faudra avoir recours à la directivité pour améliorer l’émergence du signal utile. Enfin, dans un contexte de RSB favorable, la compression du signal bruité, associée à des constantes de temps rapides, réduira le gain effectif sur le signal ; c’est la perte de gain cible.
Les conséquences techniques de cette recherche de compensation du recrutement par la compression seront traitées dans la partie dédiée à la revue de littérature.
4 Les mesures de l’amélioration du RSB
Dans ce premier chapitre de la revue de littérature, nous avons cherché dans les études scientifiques quelles étaient les métriques courantes pour mesurer l’amélioration du RSB, avant d’aborder les conséquences dans le chapitre suivant. Précisons notre choix dans l’usage des termes, qui ne font pas consensus, ni en français, ni en anglais.
mesure objective : mesure quantifiable dans une situation précise, qu’elle soit clinique ou technique (vision alternative : concerne l’appareil auditif, l’objet).
mesure subjective : requiert l’avis ou le ressenti du patient, sous forme de questionnaire de préférence (vision alternative : concerne le patient, le sujet).
Par exemple, l’amélioration du RSB peut être mesurée techniquement et éventuellement corrélée à l’amélioration objective clinique de l’intelligibilité ou à l’amélioration subjective clinique du confort d’écoute.
4.1 Les mesures cliniques
Sont présentés ici des protocoles de tests cliniques et des méthodes validées in situ qui permettent d’évaluer les métriques de mesure du RSB en entrée ou en sortie d’aides auditives via l’expérience du patient.
4.1.1 La détection de différence
L’étude “The just-noticeable difference in speech-to-noise ratio” (McShefferty et al., 2015) est une recherche clinique sur la capacité de l’oreille à détecter une modification de RSB, ce qu’ils nomment la “différence tout juste perceptible”. Pour cela, les seuils d’intelligibilité dans le bruit ont été mesurés pour plusieurs RSB chez 69 participants normo-entendants et malentendants. Il en ressort que, en moyenne, les participants ont détecté des variations de 3dB de RSB, ce qui confirme la seule étude antérieure connue sur le sujet. En revanche, dans les études menées avec un bruit large bande, la variation détectée était de 1,4dB pour les malentendants. Les auteurs mettent cette variation sur le compte de l’effort d’écoute significativement augmenté en présence d’un bruit respectant le spectre de parole, sans modulation, comme ils l’ont pratiqué. Ils en concluent que l’amélioration du RSB par une aide auditive doit être au minimum de 3dB pour présenter un avantage dans le bruit quotidien.
4.1.2 L’effort d’écoute
Nous avons retenu une étude systématique qualitative sur le sujet de l’effort d’écoute, largement traité. “Working Memory and Hearing Aid Processing: Literature Findings, Future Directions, and Clinical Applications” (Souza et al., 2015) passe en revue les liens établis entre la mémoire de travail et la perception de la parole. Le papier est paru dans la revue Frontiers in Psychology, preuve de transdisciplinarité du sujet.
Première donnée capitale, la capacité de mémoire de travail varie fortement d’un individu à l’autre. Cela est à considérer dans l’interprétation des données qui auront une forte variance. Ensuite, trois types de traitements du signal sont pris en compte pour être reliés à la mémoire de travail, mesurée via une tâche d’empan de lecture.
une compression dynamique large bande à action rapide, qui lisse l’enveloppe d’amplitude du signal d’entrée (4 études)
la réduction numérique du bruit, qui peut supprimer par inadvertance les composantes du signal vocal en supprimant le bruit (8 études)
et la compression de fréquence, qui modifie la relation entre les pics spectraux (3 études)
Le désavantage de la compression rapide, définie par un temps de retour inférieur à 200ms, est clairement établi pour les sujets à faible capacité de mémoire de travail. En revanche, les deux autres traitements n’agissent pas distinctement sur la mesure.
Pour aller plus loin, l’étude propose en discussion de mesurer l’effet cumulatif de la dégradation du signal avec la perte auditive et la quantité ou le type de bruit ambiant. En effet, c’est en décrivant objectivement les effets des différentes conditions de traitement du signal, comme l’amélioration du RSB ou la distorsion de la parole, que certains facteurs de confusion, variant avec la mémoire de travail, pourront être éliminés.
“Validation of a simple response-time measure of listening effort” (Pals et al., 2015) apporte une validation de l’utilisation du temps de réponse comme évaluation de l’effort d’écoute. Cette notion sera utile pour accéder simplement à une mesure objective de l’amélioration du RSB via une seconde variable covariante.
Dans les termes des auteurs, “l’expérience d’écoute totale” est visée par l’étude. Un paradigme à double tâche est mis en place et on mesure deux paramètres :
le temps de réponse verbale aux stimuli auditifs, dans cinq conditions de RSB,
le temps de réponse à une tâche visuelle.
Il est montré que l’intelligibilité de la parole est corrélée au temps de réponse verbale. Le papier met en avant la simplicité de la mesure de ces durées, permettant un accès simple à l’effort d’écoute.
La réponse de la pupille est une autre donnée physiologique mesurable. Dans “Impact of stimulus-related factors and hearing impairment on listening effort as indicated by pupil dilation” (Ohlenforst et al., 2017), il est reconnu que de nombreuses études ont confirmé un lien entre le RSB, le type de bruit et l’effort d’écoute mesuré par la dilatation pupillaire. Mais on a observé une difficulté supplémentaire, non mesurée, pour les malentendants par rapport aux normo-entendants. Pour combler ce manque, cette étude examine donc le lien entre :
la perte auditive,
une gamme de RSB, correspondant à des performances de reconnaissance de phrases variant de 0 à 100%,
le type de bruit masquant,
la dilatation pupillaire lors de l’épreuve de reconnaissance de phrase dans le bruit.
Pour un même niveau d’intelligibilité, il est alors prouvé qu’il peut être obtenu soit par un normo-entendant qui ne produit pas d’effort – dilatation pupillaire faible – soit par un malentendant exerçant un effort d’écoute prononcé – dilatation pupillaire forte. La difficulté de compréhension dans le bruit est objectivée par cette mesure très accessible.
Par ailleurs, l’étude “Pupil response as an indication of effortful listening: the influence of sentence intelligibility” (Zekveld et al., 2010) avait justement pour but d’évaluer l’influence de l’intelligibilité sur la réponse pupillaire. Pour cela, plusieurs seuils ont été utilisés : 50, 71 et 84% de bonnes réponses. Pour les 38 sujets normo-entendants participants, plusieurs niveaux de RSB en bruit stationnaire ont été testés. Ainsi, il a été possible de déterminer que la réponse pupillaire varie bien en fonction de l’intelligibilité, ce que les auteurs expliquent par l’effort supplémentaire fourni. De plus, la dilatation était la plus prononcée lors de la recherche du seuil à 50%. En revanche, ils n’ont pas mis en évidence de dilatation – donc d’effort – supplémentaire entre le seuil 71% et le seuil 84%, ce qui s’expliquerait par une plus faible variation de la difficulté entre ces deux derniers seuils.
Enfin, le dernier résultat de l’étude tempère ce lien par la subjectivité : il n’a pas été trouvé de corrélation entre le score individuel d’intelligibilité, la mesure pupillaire et les scores subjectifs d’effort et de performance établis par questionnaire (respectivement de “aucun effort” à “effort très élevé” et de “aucune phrase intelligible” à “toutes les phrases intelligibles”). Nous introduisons par ce résultat la notion de préférence individuelle qui sera abordée plus loin.
4.1.3 La pente de la courbe psychométrique
Pour poursuivre sur cette notion de variation du seuil, “Variations in the Slope of the Psychometric Functions for Speech Intelligibility: A Systematic Survey” (MacPherson & Akeroyd, 2014) interroge la pente de la courbe psychométrique lors des tests d’intelligibilité via une revue systématique.
Ils sont partis du constat que la plupart des études ne faisaient qu’analyser le seuil d’intelligibilité ; 885 courbes psychométriques issues de 139 études ont été réanalysées via leurs pentes respectives. On constate une forte variabilité de cette pente autour du seuil : entre 1% par dB et jusqu’à 44% par dB, avec une moyenne à 6,6% par dB. Le type de bruit de masquage et le nombre de sources semblent être les facteurs majeurs influençant la pente de la fonction psychométrique.
Les données ont été ajustées à la fonction logistique (2) ci-après. Elle donne P en pourcentage d’éléments correctement identifiés, et prend en paramètres x le RSB en décibels, c le RSB auquel on à P = 50% et m la pente de la fonction pour x = c. La pente de la fonction (en % par dB) est alors égale à −25m. Les données ayant un trop faible ajustement à la fonction logistique ont été écartées. \[P = 100\left(\dfrac{1}{1+ e^{m(x-c)}}\right)\](2)
Cette approche paramétrique est décrite en détail par “Model-free estimation of the psychometric function” (Zychaluk & Foster, 2009), qui en trace les limites applicables. Ce papier technique est paru dans Attention, Perception, & Psychophysics, mais il utilise des données liées à l’audition pour l’exemple : la détection d’un bref silence au milieu d’un bruit. Il est dit en conclusion qu’un ajustement des données à un modèle psychométrique non adapté peut aboutir à des interprétations fallacieuses.
Au vu de ces résultats, il conviendra de se remémorer que le matériel vocal est d’une importance capitale dans la mise en œuvre des tests dans le bruit et donc dans l’analyse des résultats issus de ces tests : la prédictibilité du signal et la similarité entre le signal et le bruit peuvent faire varier la pente – respectivement de 7,1 à 13,8% par dB et de 3,4 à 5% par dB. Le corpus même de phrases utilisées (CRM, HINT, IEEE, SSI) fait varier la pente de 4,8% à 17,1% par dB si le bruit masquant est statique.
On peut retenir de l’étude “Psychometric Functions of Dual-Task Paradigms for Measuring Listening Effort” (Wu et al., 2016) que la mesure de la fonction psychométrique en double tâche est difficile à corréler au RSB. En effet, chez les 24 malentendants testés dans l’expérience n°2, le temps de réponse – dont on a montré précédemment qu’il est lié à l’intelligibilité – reste similaire pour les RSB favorables et pour les RSB défavorables. Une raison invoquée serait un désengagement des sujets lorsque le bruit devient trop masquant ; ils répondraient alors rapidement pour soulager leur surcharge mentale. Cela implique un fort biais dans l’utilisation d’une double tâche lors de la recherche d’une courbe psychométrique complète – seuil et pente – pour plusieurs RSB.
Parmi les 11 RSB testés, toujours dans l’expérience n°2 qui vise à confronter les résultats des jeunes normo-entendants de l’expérience n°1, deux tâches visuelles secondaires de difficultés différentes sont traitées, ce qui représentent 22 conditions différentes. Notons que pour les RSB intermédiaires, le temps de réponse s’accroît, comme attendu, avec la difficulté de compréhension. En revanche, les auteurs ne s’expliquent pas pourquoi seuls les malentendants ont répondu avoir produit subjectivement plus d’effort lorsque les RSB devenaient défavorables pour les tâches faciles que pour les tâches difficiles. Dans la littérature, la relation entre ces paramètres reste indéterminée.
4.1.4 La préférence individuelle
Comme on l’a déjà évoquée plus haut, une forte variabilité interindividuelle est provoquée par la notion de préférence subjective. Nous avons retenu deux études pour mettre cet effet en avant. Tout d’abord, “The Effects of Varying Directional Bandwidth in Hearing Aid Users’ Preference and Speech-in-Noise Performance” (Goyette et al., 2018) a proposé de faire varier la bande passante d’un microphone directionnel (omnidirectionnel, directionnel total, directionnel au-dessus de 900Hz, directionnel au-dessus de 2kHz) puis d’interroger 10 normo-entendants ainsi que 10 malentendants sur leur préférence ; les performances de reconnaissance de la parole ont également été testées. Si l’étude parvient bien à conclure à une préférence globale pour une faible directivité au sein des deux populations – sauf au-dessus de 2kHz où aucune différence n’est relevée – , les résultats objectifs montrent l’inverse : un élargissement de la bande-passante de la directivité améliore la compréhension. “L’audibilité du bruit en sortie d’aides auditives deviendrait objectivable à partir de 10dB au-dessus du seuil” précisent les auteurs en conclusion. Et puisque cette capacité de détection varie individuellement en fonction du bruit de fond, la préférence pour l’omnidirectionnel pourrait être moins importante en condition réelle.
L’étude “Estimation of Signal-to-Noise Ratios in Realistic Sound Scenarios” (Smeds et al., 2015) avait tenté de répondre à cette question du RSB en condition réelle : si on veut tester le seuil d’intelligibilité à un RSB fixe, à combien le fixe-t-on pour s’approcher de la réalité ? D’après les enregistrements réalisés dans le bruit quotidien en pondération A de 20 utilisateurs d’aides auditives, des RSB positifs sont rencontrés la plupart du temps ; rarement le RSB ne descend au-dessous de 5dB. Ce résultat écologique est fondamental, car on verra que l’évaluation technique des performances des aides auditives dans le bruit porte sur des RSB bien moins favorables, alors que les utilisateurs moyens, entre 18 et 84 ans ici, y sont peu confrontés.
4.2 Les mesures techniques
Dans cette section, nous présentons les protocoles techniques et les méthodes validées en laboratoire qui permettent d’évaluer les métriques de mesure du RSB en entrée et en sortie d’aides auditives, sans l’intervention du patient.
Le rapport comparatif “Objective Quality and Intelligibility Prediction for Users of Assistive Listening Devices: Advantages and limitations of existing tools” (Falk et al., 2015) met en confrontation 12 outils de prédiction de l’intelligibilité dans le bruit. Il nous indique qu’il existe trois raisons à la mesure technique :
lors de la conception, afin de déterminer les paramètres optimaux des algorithmes, dont les effets peuvent être contre-productifs sur l’intelligibilité,
lors de l’adaptation prothétique, afin de fournir des préréglages adéquats ; les réglages qui offrent une intelligibilité optimale peuvent ne pas être ceux qui donnent une qualité maximale,
lors du port des aides auditives, afin d’adapter les algorithmes à l’environnement bruyant, dans une boucle rétroactive en temps réel.
Par ailleurs, lorsqu’il s’agit d’évaluer techniquement les performances des aides auditives dans le bruit, deux approches s’opposent dans la mise en œuvre :
soit le bruit est fixe et le signal varie : on réalise un test clinique d'intelligibilité,
soit le signal est fixe et le bruit varie : on procède à un test de performance des appareils.
4.2.1 Les indices prédictifs non intrusifs
La méthode non intrusive est définie par le fait qu’elle ne nécessite pas de comparaison au signal de référence dans le silence.
Historiquement développé par les laboratoires Bell pour mesurer l’intelligibilité d’un signal transmis par téléphone, puis formalisé par French et Steinberg en 1947, l’Articulation Index, ou AI, porte un nom qui prête à confusion. En effet, articulation fait référence à la faculté d’émission de la parole alors qu’on parle bien de sa réception. L’indice d’articulation a été remplacé par le Speech Intelligibility Index, ou SII, formalisé dans la norme américaine “Methods for Calculation of the Speech Intelligibility Index” (ANSI & ASA, 2017). Le groupe de travail de l’Acoustical Society of America agrège ses travaux sur le site sii.to.
D’après “The Speech Intelligibility Index: What is it and what’s it good for?” (Hornsby, 2004), le concept reste le même : pondérer chaque bande de fréquence d’un signal par l’importance qu’elle revêt dans l’intelligibilité globale. Il s’agit d’une somme de contributions. Variant de 0 à 1, sa valeur (3) quantifie l’émergence des indices vocaux : \[SII = \sum_{i=1}^{n}I_i A_i\](3)
n correspond au nombre de bande considérées (6 bandes d’octave, 18 bandes de \(\scriptstyle 1/3\) d’octave ou 21 bandes critiques),
Ii est un indice d’importance de la bande fréquentielle i concernée dans la compréhension de la parole,
Ai est l’audibilité des indices vocaux, directement liée au RSB, dans la bande i concernée.
Citons par ailleurs d’autres paramètres évoqués dans les Cahiers de l’Audition “Intelligibilité prédite, intelligibilité perçue” (Delerce, 2013) et introduit par les méthodologies NAL et DSL pour parfaire le SII dans le domaine de l’audiologie prothétique :
Di, le facteur de distorsion liée à l’augmentation du niveau de la parole,
S, le facteur de désensibilisation liée à la perte d’audition,
K, un facteur lié à l’âge de l’individu.
En effet, l’étude “Extending the articulation index to account for non-linear distortions introduced by noise-suppression algorithms” (Loizou & Ma, 2011) pointait l’absence de considération de la distorsion apportée par la non-linéarité des algorithmes, notamment la compression dynamique large bande, l’écrêtage et la réduction du bruit. Ainsi, ils avaient introduit le fractional AI, ou fAI, dont la prédiction est fortement corrélée avec les scores de compréhension observés.
En acoustique architecturale, on utilisera volontiers le Speech Transmission Index, ou STI, et dans sa version rapide RaSTI, qui est une mesure prédictive de l’intelligibilité de la parole via la modulation apportée par un système auditif ou la propagation du son dans une salle. Variant également de 0 (inintelligible) à 1 (excellent), il est à mettre en parallèle avec le %-ALCons qui représente le pourcentage de perte sur l’articulation des consonnes, de 100% (inintelligible) à 0% (excellent).
Nota bene : les tests utilisés pour évaluer les implants cochléaires (ModA, SRMR-CI) ne seront pas abordés.
Les limites du AI et du SII
L’étude “A Speech Intelligibility Index-based approach to predict the speech reception threshold for sentences in fluctuating noise for normal-hearing listeners” (Rhebergen & Versfeld, 2005) tente d’établir une prédiction du seuil d’intelligibilité via la lecture du SII dans un bruit fluctuant. Il en ressort que le SII ne permet pas de rendre compte de l’intelligibilité instantanée car il est évalué sur le long terme alors que la compression de l’aide auditive agit rapidement dans un bruit fluctuant. Ils proposent donc d’étendre la mise en œuvre du SII en découpant le signal de test en plusieurs sous-parties dont on mesurera les SII individuellement.
4.2.2 Les indices prédictifs intrusifs
La méthode intrusive signifie que nous avons besoin de connaître le signal de référence dans le calme, pour le comparer avec le signal bruité en sortie d’aide auditive.
Onze de ces méthodes sont évaluées dans “An Evaluation of Intrusive Instrumental Intelligibility Metrics” (Kuyk et al., 2018). Nous retenons les plus couramment citées et utilisées. Pour commencer, le Short-Time Objective Intelligibility, ou STOI, est basé sur un modèle auditif de normo-entendant ; il vise à fournir un indice d’intelligibilité à court terme. De courts segments de 386ms sont prélevés sur le signal décomposé en \(\scriptstyle 1/3\) d’octave. On introduit une distorsion par écrêtage sur le signal de référence puis on compare son enveloppe temporelle au signal à évaluer. S’il a été conçu pour modéliser les effets du bruit et de sa suppression par les algorithmes de réduction, il ne prend pas en compte la perte auditive.
Le PErceptual MOdel Quality, ou PEMO-Q, a été présenté dans “PEMO-Q—A New Method for Objective Audio Quality Assessment Using a Model of Auditory Perception” (Huber & Kollmeier, 2006). Il s’agit d’un algorithme qui prédit la qualité perçue d’un signal audio au travers d’un modèle psychoacoustique. Plus précisément, il prédit la perception de la dégradation du signal par les codecs audio en fonction des modulations théoriques d’amplitude par filtre auditif ERB (Equivalent Rectangular Bandwidth). Il permet de mettre en évidence de très faibles variations qui seront perçues comme néfastes pour la qualité du signal. Basé sur une mesure perceptuelle de similarité, ou Perceptual Similarity Measure, PSM, il varie de −1 à 1, bien qu’aucune valeur négative ne soit observée. Un indice instantané PSMt est calculé en permanence, pondérant l’indice final. Ce qui implique que PEMO-Q est valide sur le long terme.
Un modèle évolué, le PEMO-Q-HI, est publié dans “Predicting the perceived sound quality of frequency-compressed speech” (Huber et al., 2014) pour prendre en compte la perte auditive. D’abord limité à la réduction linéaire de la dynamique résiduelle par l’atteinte des cellules ciliées internes, le modèle est de nouveau amélioré pour prendre en compte la réduction de la sélectivité fréquentielle et le recrutement dus à la perte des cellules ciliées externes. Le PEMO-Q-HI fournit alors une excellente prédiction de la qualité du signal perçue par les malentendants à partir de leurs audiogrammes.
James M. Kates, ingénieur en génie électrique et chercheur à l’université du Colorado, diplômé du MIT en 1972, est l’auteur le plus présent de cette revue de littérature technique. Ses études concernent le traitement du signal et la prédiction de ses effets dans les aides auditives. Il a développé deux indices complémentaires : HASPI et HASQI.
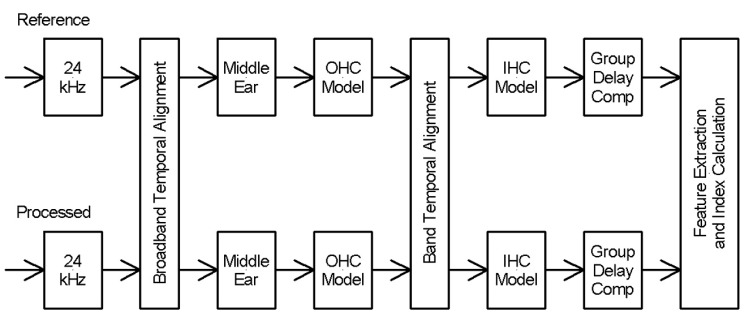
L’indice de perception de la parole pour les aides auditives est développé dans “The Hearing-Aid Speech Perception Index (HASPI)” (J. M. Kates & Arehart, 2014b). Le modèle perceptif sur lequel il se base incorpore lui aussi les effets de la perte auditive neurosensorielle. Le schéma fonctionnel de l’algorithme comparatif indique que les deux signaux à comparer – signal bruité en sortie d’aide auditive et signal de référence – passent chacun par des filtres modélisant l’oreille moyenne, puis les cellules ciliées externes et enfin les cellules ciliées internes. Ainsi, l’HASPI peut être appliqué aux normo-entendants comme aux malentendants ; il suffit pour cela d’appliquer les filtres correspondants.
Figure 11: Schéma fonctionnel de l’HASPI montrant la comparaison du signal de référence et du signal bruité – J. M. Kates \& Arehart, 2014b
L’avantage du post-traitement est qu’il gère plusieurs mécanismes dégradant simultanément l’enveloppe du signal, sa structure temporelle fine et sa répartition fréquentielle sur le long terme. Il est mis en concurrence avec trois autres indices :
le Coherence Speech Intelligibility Index, ou CSII, qui se base sur l’analyse de la structure fine et la répartition en fréquence de petits segments dont on calcule le “rapport-signal-sur-distorsion”. Trois régions d’intensité – faible, moyen et fort – sont traités séparément.
le Short-Time Envelope Correlation Index, ou STECI, basé sur STOI mais amélioré par le modèle psychoacoustique. Les échantillons d’enveloppe se chevauchent de 50% et sont prélevés sur 32 bandes de fréquence. Là encore, seule l’enveloppe très court terme est prise en compte.
la corrélation cepstrale. Celle-ci est basée sur l’analyse des similarités dans le spectre du signal, par application d’une transformée de Fourier inverse sur le logarithme du spectre lui-même (4). Dans le monde cepstrale, on obtient une quéfrence fondamentale et des rhamoniques visibles comme des pics dans le cepstre et dont les amplitudes sont des coefficients à comparer avec ceux du signal d’origine. \[C_{f(t)} = \mathcal{F}^{-1}\big\{\ln\big({|\mathcal{F}\{f(t)\}|}\big)\big\}\](4)
Tout type de traitement du signal peut être évalué avec l’HASPI. Dans le papier de 2014, ce sont bruit et distorsion, compression fréquentielle et suppression du bruit qui sont comparés entre normo-entendants et malentendants. L’HASPI apparaît comme étant plus robuste (ses prédictions sont meilleures) et plus flexible (il s’applique dans plus de contextes) que ses trois concurrents.
La conception de l’indice complémentaire, “The Hearing-Aid Speech Quality Index (HASQI) Version 2” (J. M. Kates & Arehart, 2014a) nous apprend qu’il est bâti sur le produit de deux termes. Le premier terme non-linéaire correspond à la mesure de la modulation d’enveloppe, telle que réalisée dans HASPI, et une corrélation croisée d’un signal normalisé par bande de fréquence. Le deuxième terme linéaire compare les spectres à long terme et les pentes spectrales. La mesure d’enveloppe est sensible au comportement dynamique du signal associé aux consonnes, tandis que la mesure de corrélation croisée est plus sensible à la préservation des harmoniques dans les voyelles en régime permanent. L’ajustement de l’indice a été réalisé sur une cohorte de 14 normo-entendants et 15 malentendants et a objectivé la qualité de six types d’algorithmes : bruit et distorsion, compression fréquentielle, suppression du bruit, vocodeur de bruit, annulation du larsen et bruit fluctuant.
En complément, ces indices ont été mis en œuvre dans “Using Objective Metrics to Measure Hearing Aid Performance” (Kates et al., 2018) pour mettre en concurrence plusieurs gammes d’appareils auditifs. Des variations significatives sont observées selon les fabricants, selon le RSB en entrée et selon les paramètres des réglages. Mais les prédictions données par HASPI et HASQI ne montrent pas de différence entre les gammes d’appareils. Les auteurs reconnaissent en conclusion que ces indices ne peuvent en aucun cas suffire à caractériser la réussite ou non d’un appareillage ; d’autres études devront tenter d’établir un lien entre les scores objectifs et la satisfaction des utilisateurs.
4.2.3 Les techniques de mesure
Nous présentons maintenant les procédures opérationnelles pertinentes décrivant les relevés acoustiques en laboratoire ou en chambre anéchoïque.
Lorsqu’il s’agit de mettre en évidence les différences entre deux enregistrements audio, on procède généralement à un null test : l’addition du signal bruité et du signal de référence dont on inverse la phase permet 1. d’annuler les signaux identiques et 2. de faire apparaître les écarts de façon claire. C’est le principe de la méthode présentée dans “A Method to Measure the Effect of Noise Reduction Algorithms Using Simultaneous Speech and Noise” (Hagerman & Olofsson, 2004).
Il y est proposé d’enregistrer deux fois la sortie de l’aide auditive – bruit en phase puis bruit en opposition de phase – pour plusieurs RSB puis de séparer le bruit du signal à partir du signal “propre”, connu. De nombreuses études cliniques utiliseront ce procédé acoustique pour reconstruire le RSB et ainsi déterminer deux gains :
le gain apporté au signal, en fonction du RSB ; maîtriser ce gain est le but principal de la réhabilitation auditive non linéaire,
le gain apporté au bruit, en fonction du RSB ; il devrait s’agir d’un effet délétère, non souhaité. Les aides auditives tentent de le minimiser, voire de le rendre négatif.
La thèse “The role of aided signal-to-noise ratio in aided speech perception in noise” (Miller, 2013) explicite l’enregistrement en sortie par la formule suivante : \[\begin{cases}A_{(out)} = S_{(out)} + N_{(out)}\\B_{(out)} = S_{(out)} - N_{(out)}\end{cases}\](5)
Avec A pour le premier enregistrement, B pour le deuxième, S pour signal, N pour le bruit noise.
Il vient alors la possibilité d’additionner ces signaux pour obtenir le signal, ou de les soustraire pour obtenir le bruit (6), à la condition qu’ils soient parfaitement synchronisés. Les protocoles de mise en œuvre proposent pour cela d’aligner les enregistrements à l’aide d’un son pur initial dont on pourra ajuster visuellement les sinusoïdes, ou alors d’automatiser l’alignement en contrôlant l’absence de bruit résiduel (cf. Mémoire D.E. d’Audioprothèse de Franck Leclère, 2014, “Estimation du rapport signal sur bruit en sortie d’aide auditive ; mise en œuvre, application”). \[\begin{cases}A_{(out)} + B_{(out)} = S_{(out)} + N_{(out)} + S_{(out)} - N_{(out)} = 2S_{(out)} \\A_{(out)} - B_{(out)} = S_{(out)} + N_{(out)} - S_{(out)} + N_{(out)} = 2N_{(out)}\end{cases}\](6)
Les mises en œuvre informatisée de cette procédure, notamment sous Matlab et RStudio, utilisent le préfixe m (pour minus) pour signaler que la phase du signal est inversée, p pour indiquer une addition des signaux et SNRx lorsque le RSB vaut x. Cela donne des fichiers dont le nom sera par exemple p1_aided_dnr_dir_on/P90R _auto_SNRm10_mSpN.wav pour l’enregistrement en sortie d’un Phonak Paradise 90 R, avec réduction directionnelle du bruit, en mode automatique, à un RSB de −10dB, où le signal est inversé par rapport au bruit.
Nous avons relevé deux études qui tentent d’étendre la méthode Hagerman \& Olofsson à plusieurs sources sonores. La première a été menée par le groupe Sivantos et présentée lors de l’ICASSP, International Conference on Acoustics, Speech and Signal Processing.
Elle se nomme “Directionality assessment of adaptive binaural beamforming with noise suppression in hearing aids” (Aubreville & Petrausch, 2015). Les auteurs ajoutent la notion de source interférente dans le but d’évaluer la performance des algorithmes à directivité adaptative. Il en découle un “rapport interférant sur cible”, ou “Interferer To Target Ratio”, qui dépend de l’angle dans le domaine fréquentiel : \(ITR(f,\varPhi_v)\).
Grâce à ce concept, il a été possible d’évaluer les performances dans trois conditions : omnidirectionnelle dans le calme, directionnelle monaurale dans le bruit et directionnelle binaurale dans le bruit. Les résultats sont donnés par un indice séquentiel de directivité pondéré par l’indice d’articulation, le Articulation based sequential directivity index, ou sAIDI.
Vient ensuite l’étude “Evaluation of Noise Reduction Algorithms in Hearing Aids for Multiple Signals From Equal or Different Directions” (Husstedt et al., 2018) initialement présentée lors d’un congrès ISAAR, International Symposium on Auditory and Audiological Research. Leur calcul matriciel permet d’étendre encore la procédure d’inversion de phase à autant de sources que désirées. La mesure présentée consistait à évaluer les performances d’un appareil auditif placé au milieu de 8 haut-parleurs. Ce sont quatre réglages qui étaient comparés ici : avec et sans réduction de bruit vs microphone omnidirectionnel et directionnel.
Bien que le papier présente un concept mathématique, notons tout de même les résultats pour le BTE testé :
une amélioration du RSB indépendante de la direction lorsque la réduction du bruit est activée avec un réglage de microphone omnidirectionnel,
une amélioration du RSB dépendante de la direction pour une directivité fixe,
un maximum d’amélioration du RSB à 180° avec une réduction de bruit activée et une directivité fixe.
Pour terminer cette revue des techniques de mesure, nous avons choisi d’aborder “A method to remove differences in frequency response between commercial hearing aids to allow direct comparison of the sound quality of hearing-aid features” (Houben et al., 2011). Les auteurs y proposent de comparer les aides auditives entre elles en nivelant les différences de réponse en fréquence. Pour ce faire, trois étapes sont proposées :
ajuster manuellement et finement le gain d'insertion,
ajouter une limitation de bande-passante de 100Hz à 5,8kHz sur les enregistrements en sortie d’aides auditives, pour permettre aux appareils basiques d’être comparés aux modèles qui gèrent une plage de fréquences étendue,
appliquer un filtre inverse aux réglages de l’aide auditive sur l’étendue de la bande-passante limitée.
Ce filtre inverse est appliqué sur les réglages en entrée, en fonction de l’enregistrement en sortie, afin de compenser en temps réel les algorithmes de traitement du signal activés. Pour vérifier l’homogénéité des enregistrements, une mesure objective – via l’HASQI – et deux mesures subjectives – détection de différence et préférence d’écoute – sont réalisées.
Les résultats ont montré que les points 1. et 2. ne sont pas suffisants à eux seuls pour supprimer les différences entre appareils. La perception identique est trouvée lorsqu’on annule la réponse en fréquence des aides auditives, cela étant confirmé par le test objectif HASQI et les tests subjectifs individuels. Grâce à cette méthode, il est possible de comparer les performances des algorithmes non-linéaires, notamment de réduction du bruit.
4.2.4 Les mises en œuvre
À travers les effets de la directivité microphonique sur l’amélioration du RSB, une étude pose la question de la conformité de la mesure simulée par rapport aux conditions réelles. Les auteurs de “Performance of directional microphones for hearing aids: real-world versus simulation” (Compton-Conley et al., 2004) ont recréé un environnement bruyant de restaurant via trois protocoles de simulation qu’ils vont comparer à la réalité :
le R-Space, un ensemble de 8 microphones répartis de façon circulaire et qui enregistrent la scène sonore. Les enregistrements seront rejoués par 8 haut-parleurs répartis de la même manière autour du sujet,
IAC 180, – Industrial Acoustics Company, marque de la cabine acoustique – méthode d’évaluation traditionnelle, avec un bruit issu d’un seul haut-parleur placé derrière le sujet,
IAC 90, idem mais au-dessus du sujet.
Un mannequin de mesure KEMAR est utilisé pour évaluer l’indice de directivité pondéré par l’indice d’articulation, Articulation Index-weighted Directivity Index, ou AI-DI [déjà cité sous sa forme séquentielle dans l’étude (Aubreville & Petrausch, 2015)]. Trois réglages microphoniques sont évalués : omnidirectionnel, supercardioïde et hypercardioïde. En mode simulation, chaque environnement est évalué par un test adaptatif d’intelligibilité dans le bruit puis comparé aux performances mesurées en condition réelle.
Dans le but de confronter les résultats de la simulation à ceux en situation réelle, les auteurs se sont assurés que le spectre à long terme du bruit ambiant dans le restaurant était conforme au bruit issu du HINT. Douze malentendants ont pris part à ce test d’intelligibilité de la parole.
Figure 12: Seuils d’intelligibilité moyens (dB) pour des phrases en fonction de 3 réglages microphoniques et de 4 conditions environnementales pour le rendu du bruit – Compton-Conley et al., 2004
Si on peut noter, sur la figure 12, que les résultats sont systématiquement meilleurs avec une directivité hypercardioïde (Array), il est plus pertinent pour notre revue de littérature de relever la similarité entre les résultats live et R-Space. En effet, cette méthode de simulation par enregistrement puis restitution spatiale du bruit permet de rendre compte des performances réelles des aides auditives testées en présence de bruit.
En conclusion de cette revue des mesures techniques, nous présenterons le travail de Christophe Lesimple [chercheur en audiologie clinique au sein de Bernafon et qui a intégré le groupe Sonova pendant la rédaction de ce mémoire], avec lequel nous nous sommes entretenus. L’analyse de ses recherches a été particulièrement bénéfique dans le développement de notre écriture.
Dans le poster “Hearing aid performance characterized by apparent SNR estimation to predict speech intelligibility in noise with hearing impaired listeners” (Lesimple et al., 2018), l’équipe de chercheurs en audiologie de Bernafon s’est demandé si on pouvait caractériser la performance d’une aide auditive par le RSB mesuré et ainsi prédire l’intelligibilité dans le bruit. En d’autres termes, la variation du score d’intelligibilité dans le bruit est-elle corrélée à l’amélioration effective du RSB ?
Pour répondre à cette interrogation, nous aurons besoin d’introduire l’étude “Standard audiograms for the IEC 60118-15 measurement procedure” (Bisgaard et al., 2010) dont l’objectif a été de créer un ensemble de dix audiogrammes fictifs mais représentatifs des observations en pratique clinique.
Un ensemble de 28.244 audiogrammes issus du service ORL de l’hôpital de Stockholm a été analysé ; statistiquement, l’âge moyen des patients était de 67,5 ans avec une médiane à 72,9 ans. La perte moyenne sur 500Hz, 1kHz et 2kHz était de 40,9dB. L’étendue des fréquences testées allait de 250Hz à 6kHz par demi-octave.
La standardisation des dix audiogrammes est donnée comme suit :
N1 à N7 concernent les courbes plates à modérément pentues et des pertes très légères (1) à profondes (7),
S1 à S3 concernent les courbes en pente de ski et des pertes très légères (1) à moyennes de deuxième degré (3) – S pour steep, abrupte.
Ces travaux de base étant présentés, revenons au poster dans lequel trois étapes des tests sont mises en œuvre.
L’évaluation des appareils: l’adaptation prothétique de type N3 est pratiquée via la méthodologie NAL NL2 avec des dômes fermés sur un KEMAR. Dans ce test comparatif, les deux aides auditives possèdent les mêmes caractéristiques de compression dynamique mais diffèrent par leurs réglages de directivité et de réduction du bruit. L’évaluation du gain pour chaque niveau de RSB (de −10 à +10dB) a été réalisée par la méthode Hagerman \& Olofsson citée dans la section précédente. Conclusion : la performance des algorithmes sur le RSB en sortie est dépendante du RSB considéré en entrée.
La recherche du seuil d'intelligibilité : sur 29 sujets évalués lors d’un test vocal dans le bruit adaptatif, on étudie les scores à 50% et 80% pour chaque niveau de RSB. Conclusion : l’amélioration du seuil d’intelligibilité – avec et sans appareil – dépend du RSB considéré. Ce niveau dépend lui-même du type de bruit, du matériel vocal, de la méthode de notation et de la localisation du signal et du bruit.
L’analyse des données brutes : les résultats précédents sont corrélés à une fonction logistique qui prédit la réponse psychométrique, sujet abordé dans les mesures cliniques. On observe qu’une amélioration du seuil d’intelligibilité se traduit par une verticalisation de la courbe psychométrique. Le bénéfice de l’amplification passe par un pic d’amplitude qui dépend du RSB de façon individuelle. Conclusion : la modification du seuil d’intelligibilité à 50% donne lieu à un déplacement du pic d’amélioration dans les RSB négatifs (situations plus difficiles) mais ne permet pas de détecter de changement dans la pente de la courbe.
En discussion, cette étude introduit la notion de target loss, ou perte de sonie, pour exprimer un écart au SIBX% recherché. Les appareils auditifs ayant pour but d’apporter un gain sur le signal et non sur le bruit, leur bénéfice maximal sur l’intelligibilité est atteint lorsque la perte de sonie est réduite à son minimum. Ce target loss ne doit pas être confondu avec la perte de gain cible qui sera abordé dans le chapitre suivant.
4.3 La corrélation entre objectif et subjectif
Certaines expériences ont montré des corrélations ou des absences de lien entre les métriques objectives et subjectives. Nous en avons sélectionné cinq, publiées entre 2005 et 2016, et qui sont représentatives de cette recherche de cohérence.
1. La mesure adaptative du seuil d’intelligibilité apporte un biais dans la comparaison des aides auditives si le RSB n’est pas pris en compte.
En prenant du recul sur les aspects techniques et scientifiques, la publication “Theoretical Issues of Validity in the Measurement of Aided Speech Reception Threshold in Noise for Comparing Nonlinear Hearing Aid Systems” (Naylor, 2016) pose des questions théoriques sur l’écologie de la mesure clinique. Leur revue systématique analyse les conditions de RSB de onze études : les moyennes vont de −14dB à +5dB et les amplitudes de +4dB à +20dB. Cette forte variabilité les amène à conclure que l’absence de contrainte sur le RSB conduit à trois biais principaux :
la validité interne des résultats, puisque les appareils se comportent de façon imprévisible selon le RSB,
la validité écologique, si les conditions de bruit sont trop éloignées des situations réelles,
la spécificité individuelle qui peut masquer un effet réel de l’appareil.
Les auteurs invitent les concepteurs d’expériences à mieux considérer la non-linéarité de la compression afin d’obtenir des résultats cliniques fiables.
2. Une méthode de comparaison par paires permet de corréler la préférence subjective au mode de compression mais pas à la réduction du bruit.
L’étude initiale était nommée “Speech intelligibility prediction in hearing-impaired listeners based on a psychoacoustically motivated perception model” (Holube & Kollmeier, 1996) et a donné lieu à un court papier mené par la même auteure, “Subjective and objective evaluation methods of complex hearing aids” (Holube et al., 2007).
Il est proposé dans cette étude de rechercher un lien statistique entre une mesure subjective de la préférence et une mesure objective de la modulation du signal (MTF, Modulation Transfer Function) apportée par le traitement du signal. S’il est clair que la compression dynamique améliore la qualité perçue avec la modulation du signal pour les normo-entendants comme pour les malentendants, les résultats pour la réduction du bruit ne sont pas significatifs. Il est suggéré 1. que ce résultat est influencé par la perte auditive qui n’est pas prise en compte dans la mesure objective et 2. que la réduction du bruit est liée à des critères subjectifs, ce que semble confirmer l’étude suivante.
3. Une autre méthode de comparaison par paires permet de conclure à l’absence de bénéfice de la réduction du bruit ambiant sur l’intelligibilité.
Si la méthode de comparaison par paires permet d’évaluer toutes sortes de paramètres, il est nécessaire de les choisir judicieusement. Ainsi, l’étude “Methodology for quantifying perceptual effects from noise suppression systems” (Dahlquist et al., 2005) compare le seuil d’intelligibilité à un score de qualité du son en dB relatif par rapport à une condition de référence. Ce concept permet, à l’inverse de l’étude précédente, de mettre en avant des effets positifs ou négatifs des différents systèmes de réduction du bruit.
Ainsi, dans les deux conditions de bruit, les valeurs négatives d’écart Δ(sans − avec) indiquent de moins bonnes performances avec la suppression du bruit activée.
Table 1: Résultats du test d’intelligibilité (dB) avec et sans suppression du bruit dans 2 conditions de bruit – Dahlquist et al., 2005
Bruit statique aléatoire
Babil
Labo n°1
Sans traitement
−2.9
−0.9
Avec traitement
−1.7
+1.0
Δ(sans − avec)
−1.2
−1.8
Labo n°2
Sans traitement
+3.3
+6.8
Avec traitement
+5.0
+7.7
Δ(sans − avec)
−1.7
−0.8
Comme abordé au tout début de la revue des mesures cliniques, il est nécessaire d’obtenir une amélioration du RSB de 3 à 4dB pour commencer à percevoir une amélioration sur la qualité perçue du son et de 3 à 6dB pour une amélioration de l’intelligibilité de la parole. Ces effets sont si faibles que seule une méta-analyse des résultats des 60 participants sur les deux sites de test a permis de détecter une amélioration statistiquement significative. Dans le tableau 2 ci-après, la “clarté de la parole” est évaluée pour quatre types de bruit. L’astérisque indique une différence positive d’au moins 1%.
Table 2: Valeurs médianes de détection d’une différence (dB) avec et sans suppression du bruit pour la “clarté de la parole” – Dahlquist et al., 2005
Catégoried’évaluation
Bruit statiquealéatoire
Babil
Circulation
Restaurant
Clarté de la parole
Labo n°1
+0.9
+0.6*
+2.5*
+0.3*
Labo n°2
+3.7*
+1.3*
+3.6*
+1.4*
4. La préférence individuelle varie en fonction du RSB par bande de fréquence mais aussi en fonction du niveau de bruit absolu dans chaque bande.
Toujours en 2005, les auteurs de “The preferred response slopes and two-channel compression ratios in twenty listening conditions by hearing-impaired and normal-hearing listeners and their relationship to the acoustic input” (Keidser et al., 2005) montraient que la performance des réducteurs du bruit ne pouvait pas être extrapolée à partir de résultats individuels. Dans le cadre d’un filtrage haute et basse fréquence avec une coupure à 1,5kHz, on observe :
que la pente préférée du filtre est prédite par les RSB respectifs mesurés dans chacun des deux canaux,
que le niveau acoustique préféré en sortie est prédit par l’intensité absolue dans chacun des deux canaux.
Afin de mettre en évidence ces corrélations, trois paramètres de test – type de parole / type de bruit / critère d’évaluation – sont agencés de façon à produire 20 conditions différentes.
Par exemple : conversation / babil / confort d’écoute ou bien dialogue / calme / compréhension de la parole.
Cette approche a permis d’alterner les conditions de RSB entre favorable et défavorable. Dans le cas du RSB positif (favorable), les sujets ont, en général, préféré des courbes de réponses différentes, en fonction du critère d’évaluation : compréhension de la parole et confort d’écoute. Les auteurs valident l’approche des fabricants qui est d’activer une compression dynamique large bande dans plusieurs canaux de réglages avec des réductions de gain supplémentaires dans les canaux où le bruit est estimé être dominant.
5. Lorsqu’on compare les outils de prédiction de l’intelligibilité, les indices à court terme prévoient un seuil très proche de la réalité.
La troisième étude comparative “Comparison of predictive measures of speech recognition after noise reduction processing” (Smeds et al., 2014) propose de comparer les outils de prédiction en fonction du RSB et du type de réduction du bruit. Parmi les neuf mesures testées, le CSII, que nous avons abordé dans les indices prédictifs intrusifs, parvient à prédire le seuil d’intelligibilité avec une erreur de seulement 0,9dB pour les malentendants et 0,4dB pour les normo-entendants. Nous avons vu que l’HASPI, publié la même année, offrait des perfomances encore meilleure, d’après les deux autres études comparatives déjà citées (Falk et al., 2015; Kuyk et al., 2018). Malgré tout, les conclusions restent celles-ci :
\(\rightarrow\) les méthodes d’analyse à long terme, comme le SSI, semblent manquer de précision dans la prise en compte des variations rapides induites par les réducteurs de bruit, \(\rightarrow\) les méthodes d’analyse à court terme, comme le STOI, sont de meilleurs prédicteurs de la performance, seulement si elles prennent en compte la corrélation spectrale entre le signal source et le signal bruité.
Nous venons de passer en revue une quarantaine de publications qui représentent le corpus de littérature sur le sujet de la mesure de l’amélioration du RSB. Grâce à ce large panel de protocoles objectifs, subjectifs ou tentant une corrélation, nous avons répondu à notre question “Combien ?”. Demandons-nous maintenant “Jusqu’où ?” améliorer le RSB.
5 Les conséquences de l’amélioration du RSB
Lorsqu’on pousse les algorithmes d’amélioration du RSB à leur maximum, “Jusqu’où” peut-on aller avant de voir apparaître des effets contre-productifs ?
Nous allons tout d’abord décrire ces conséquences objectives sur le fonctionnement des aides auditives, puis nous confronterons les études cliniques qui les mettent à l’épreuve.
5.1 Les limites objectives
5.1.1 La perte de gain cible
Reprenons de façon plus poussée les causes et conséquences de cette “perte de gain cible” abordée dans les rappels sur la compression.
En 2009, une étude a évalué le RSB à long terme en entrée et en sortie d’aide auditive, en fonction de plusieurs critères de réglage de la compression : “Long-Term Signal-to-Noise Ratio at the Input and Output of Amplitude-Compression Systems” (Naylor & Johannesson, 2009). La procédure de séparation des signaux par inversion de phase de Hagerman \& Olofsson, appliquée à onze RSB différents, de −10dB à +10dB par pas de 2dB, et pour quatre combinaisons de paramètres temporels – soit 44 mesures – aboutit à la figure 13 ci-dessous.
Figure 13: Mesures du RSB en sortie pour une compression mono-canale de taux \texttt{2:1} selon 4 paires de constantes de temps – Naylor \& Johannesson, 2009
Plus la compression est rapide, plus la courbe bascule autour d’un point de croisement et s’éloigne de la diagonale parfaite. L’équipe d’auteurs décrit un abaissement progressif des performances du gain sur le signal utile au fur et à mesure de l’amélioration du RSB en entrée. On comprend alors que la comparaison des performances de deux aides auditives entre elles risque d’être perturbée par la variation des critères de test affectés par le RSB :
un changement du SIB cible de 50% à 80%,
un changement de la prédictabilité des phrases,
un changement de la notation par mot en une notation par phrase,
un changement de l’intelligibilité du locuteur,
un changement de binaural à monaural,
un changement du type de bruit, par exemple de non modulé à modulé,
un changement de la séparation spatiale de la parole et du bruit masquant.
D’autant que les malentendants ont chacun un besoin spécifique d’émergence de la partole dans le bruit pour atteindre la performance cible de 50% d’intelligibilité. Ce constat a conduit l’équipe suivante à mener son étude.
La lecture du SIB50 n’est pas suffisante pour caractériser les aides auditives à compression non-linéaire car l’amélioration du seuil d’intelligiblité dépend du RSB en entrée. C’est ce que nous montre l’étude “Characterizing Speech Intelligibility in Noise After Wide Dynamic Range Compression” (Rhebergen et al., 2017), très liée au poster(Lesimple et al., 2018) présenté dans le chapitre précédent. Le calcul du gain sur le signal montre que la compression dynamique large bande WDRC a des effets antagonistes selon que nous sommes en situation de RSB favorable ou défavorable :
si le signal est supérieur au bruit (RSB > 0dB), les crêtes de la parole émergent au-dessus du bruit. Alors, la compression lisse les crêtes du signal utile, dégradant le RSB de sortie,
si le bruit est supérieur au signal (RSB < 0dB), le bruit émerge au-dessus de la parole, la compression fait l’inverse (lisse le bruit), améliorant le RSB de sortie.
Définition graphique de la perte de gain cible : sur la figure 14, la courbe d(RSB) passe en négatif lorsque le RSB en entrée augmente.
Figure 14: Écart de RSB apparent entre avant et après une WDRC pour de la parole dans un bruit haché à 8Hz – Rhebergen et al., 2017
Il faudra se concentrer sur la variation du RSB, noté d(RSB), avec et sans WDRC, pour mettre en avant l’intérêt de l’algorithme sur l’amélioration de l’intelligibilité de la parole dans le bruit discontinu. Dans le bruit stationnaire, le graphe B (non représenté ici) montre la même chute dans les RSB favorables que le graphe D (représenté ci-dessus), mais la variation est nulle – donc pas d’amélioration – dans les RSB défavorables.
Cette dégradation du RSB par la compression en présence de bruit avait été précédement mesurée dans “Measuring the acoustic effects of compression amplification on speech in noise” (Souza et al., 2006), toujours via la méthode Hagerman \& Olofsson. En multi-canal, il avait été observé entre 1dB et 3dB de perte (tableau 3), d’autant plus grande que le taux de compression était elévé et le RSB favorable.
Table 3: Variation du niveau de RSB en sortie (dB) en fonction du RSB en entrée après une compression multi-canale – Souza et al., 2006
RSB en entrée
RSB en sortie aprèscompression multi-canale
Variation
−2
−3
−1
+2
0
−2
+6
+3
−3
+10
+7
−3
Une solution est discutée dans le papier “Signal-to-Noise-Ratio-Aware Dynamic Range Compression in Hearing Aids” (May et al., 2018) : corréler le temps de retour au RSB.
RSB élevé : action rapide appliquée au domaine fréquentiel et temporel de la parole,
RSB bas : action lente pour linéariser le signal fortement bruité.
Figure 15: Schéma fonctionnel de la compression liée au RSB, constituée de 3 couches de traitement : (a) analyse et synthèse basées sur la STFT, (b) analyse de la scène sonore, et (c) compression dynamique. (I)STFT pour (Inverse) Short-Time discrete Fourier Transform, ou transformée de Fourier (inverse) – May et al., 2018
La compression liée au RSB rivalise avec les deux vitesses de référence :
\(\rightarrow\) les taux de compression effectifs ont été calculés ; comme attendu, la compression rapide traditionnelle possède les taux de compression les plus forts, et la compression liée au RSB testée ici est capable d’atteindre des taux au moins aussi bons, \(\rightarrow\) la compression liée au RSB restitue les fluctuations naturelles du bruit de fond, comme le fait la compression lente de référence.
Figure 16: Analyse du RSB en entrée et en sortie pour 4 types de compression et un système linéaire – May et al., 2018
Ce que nous apprend la figure 16 : bien que tous les types de compression conduisent à une perte du gain cible plus prononcée dans les RSB favorables, le concept de la compression liée au RSB (◀) réduit cet écart face à la compression rapide (▲), sans pour autant aller jusqu’au niveau de la compression lente (▼), qui lisse les indices d’enveloppe temporelle.
L’effet de la sélection indifférenciée du niveau de parole et du niveau de bruit a été nommé “speech pause effect”, ou “effet pause de parole” dans l’étude “Measuring the long-term SNRs of static and adaptive compression amplification techniques for speech in noise” (Lai et al., 2013). En effet, la perte de gain cible apparaît car le bruit au milieu de la parole est amplifié comme s’il s’agissait d’une voix faible. Alors, il en résulte une dégradation du RSB à cause du bruit devenu plus fort. Cet effet de bord de la compression dans le bruit peut être vu soit comme une perte de gain cible sur le signal, soit comme une amplification non désiré du bruit. Dans les deux cas, il dégrade le RSB dès que la parole émerge.
À la différence de May et al. en 2018, Lai et al. avaient, en 2013, étudié la possibilité de réaliser une compression dynamique large bande Adaptative sur le RSB (AWDRC), mais en adaptant le taux de compression et non une constante de temps, par bande de fréquence.
Figure 17: Exemple de plage d’ajustement de la compression AWDRC. La ligne pleine est la fonction entrée/sortie de la WDRC d’origine – Lai et al., 2013
La zone grise sur la figure 17 représente l’étendue de l’adaptation possible en compression par déplacement des seuils et des pentes.
(LLG = gain bas, LTH = seuil bas, CR = taux de compression, HTH : seuil haut, HLG = gain haut)
Comme l’indiquent les auteurs, cette amélioration du RSB à long terme par l’AWDRC pourrait apporter une meilleure intelligibilité dans le bruit. Pour en être sûr, il faudra étudier l’impact clinique de ces méthodes.
Les études présentées dans cette section sont restées dans le domaine du laboratoire. La notion de confort d’écoute, propre à l’expérience du patient, sera abordée dans la suite notre écrit, lorsque nous allons nous intéresser aux expérimentations cliniques.
5.1.2 Les autres limites
Des commentaires importants sont à faire sur les limites que nous n’avons pas abordées dans la recherche documentaire.
Le couplage acoustique
Les considérations concernant l’adaptation prothétique n’ont pas été traitées. Or, ce point est crucial pour l’audioprothésiste ; la recherche de l’amélioration du confort et de l’intelligibilité dans le bruit passe par le réglage et l’adaptation.
Le couplage acoustique ouvert, qui représente une part de plus en plus importante du marché, a été introduit pour limiter les effets d’occlusion et favoriser la qualité du son pour des pertes faibles en basse fréquence (Magnusson et al., 2013). Cependant, les effets bénéfiques du traitement du signal sur le RSB, que ce soit via la directivité ou la réduction du bruit, sont considérablement amoindris dans le cas d’adaptations “open-fit”. Et, par corollaire, les effets néfastes sont également moins perceptibles.
Les systèmes occlus permettraient donc de maîtriser le gain et de conserver un traitement du signal homogène sur toute la plage de fréquences, notamment en compression, afin de réduire les effets de masquage.
Une technique de mesure du RSB in vivo a tout de même été repérée : “Measuring real-ear signal-to-noise ratio: application to directional hearing aids” (Bell et al., 2010). Elle propose d’évaluer l’impact de la directivité sur l’amélioration du RSB, grâce à un KEMAR puis sur oreilles réelles. Mais les résultats sont sujets à une forte variabilité interindividuelle, due aux facteurs physiologiques et mécaniques : taille de la tête, type d’embout et type d’évent.
Les effets sur la phonétique
Nous n’aurons pas développé non plus l’impact précis de la distorsion introduite par le traitement du signal sur les indices phonétiques de la parole. Dans le domaine de la phonologie, le logiciel Praat5 permet cette manipulation des sons vocaux.
Chong & Jenstad sont les auteurs d’une expérience parue en 2018 dans la revue The Medical Journal of Malaysia, SJR < 0,2(Chong & Jenstad, 2018), “Digital noise reduction in hearing aids and its acoustic effect on consonants /s/ and /z/”. Ils proposent à ce sujet d’évaluer l’effet acoustique de la réduction numérique du bruit sur les consonnes fricatives /s/ et /z/.
Dans le cas présent, l’analyse sonore a montré jusqu’à 42% d’impact sur la variabilité acoustique du son /s/ dans le bruit après traitement par un algorithme basé sur la modulation. De nombreuses autres études existent sur ce sujet, abordant des techniques et des langues variées, évaluant ainsi un large répertoire de parole dont l’articulation varie.
5.2 Les effets subjectifs
Dans notre recherche documentaire sur les effets subjectifs de l’amélioration du RSB, nous avons sélectionné 30 études cliniques. Pour cela, nous nous sommes demandé :
est-ce qu’une mesure du RSB est pratiquée en entrée ou en sortie ?
quelles sont les métriques évaluées ?
quelles sont les variables de tests ?
quelles sont les conclusions ?
L’analyse des conclusions des études est fournie en annexe 2.
Les données extraites des études sont fournies en annexe 3.
Table 4: Liste des études cliniques sélectionnées.
“Comparison of effects on subjective intelligibility and quality of speech in babble for two algorithms: A deep recurrent neural network and spectral subtraction”
“Environmental noise reduction configuration: Effects on preferences, satisfaction, and speech understanding”
5.2.1 L’amélioration du confort d’écoute
Ces 30 expériences cliniques sélectionnées font appel à tous les concepts présentés dans les chapitres précédents, ce qui permet d’en faire le bilan.
Pour le compléter, rappelons ce qu’est l’ANL, Acceptable Noise Level, ou niveau de bruit acceptable, introduit par le Dr Nabelek. Il s’agit de la mesure subjective de la différence entre le niveau de confort du signal (MCL, Most Comfortable Level) et le niveau maximum de masque (BNL, Background Noise Level). Le “test ANL” étant rentré dans le langage courant de l’audioprothésiste, nous avons choisi de ne pas le traduire.
Le confort d’écoute
Les technologies de réduction du bruit apportent donc une capacité accrue à supporter le bruit et à adhérer au port d’une aide auditive, comme le montre l’étude de Nabelek et al. [19]. Le confort d’écoute apporté par les algorithmes de réduction de bruit est subjectivement privilégié par les malentendants [1] [5] [7] [16] [18] [28], jusqu’à un certain taux d’amélioration [27].
Une différence individuelle dans la perception de la gêne sonore est à noter [6].
La préférence individuelle
La préférence individuelle peut être mesurée en terme de clarté [11], de qualité sonore [13] [30] ou de préférence par paires [15]. Dans certaines conditions environnementales, l’amélioration n’est pas perceptible [29], ou bien aucun changement de satisfaction n’est observé [2] [5].
5.2.2 La réduction de l’effort d’écoute
L’intelligibilité
Selon les conditions des études et les technologies de réduction du bruit utilisées, on trouve des résultats variables à l’amélioration du RSB. Ces conclusions contradictoires concernant l’impact sur l’intelligibilité sont assez équitablement réparties : 5 études montrent une amélioration de l’intelligibilité [5] [13] [15] [23] [27], 5 autres études rapportent qu’aucun changement notable n’est observé [2] [9] [17] [24] [25], et 4 études enfin parlent de différences individuelles liées à la perte auditive ou à la mémoire de travail [3] [4] [10] [23].
L’effort d’écoute
Cette libération des ressources cognitives apportée par l’augmentation du contraste positif entre le signal et le bruit [24] permet une diminution de l’effort d’écoute [9] [11] [12] [23] [26] [30], améliore l’apprentissage de nouveaux mots chez les enfants [22] et diminue le temps de réponse [26]. Les sujets à forte mémoire de travail bénéficient le plus de cette amélioration [23].
Le matériel
En plus de l’environnement et des caractéristiques auditives des patients, il existe une forte variabilité entre les appareils, qui peut s’expliquer par le réglage des différents algorithmes de traitement du signal [1] [6] [8] et surtout par les technologies utilisées pour influer sur le RSB :
compression linéaire ou large bande [20],
compression liée au RSB ou non [15],
réduction du bruit liée à la directivité ou non [21],
réduction du bruit liée à la compression ou non [14],
compression rapide associée à la directivité [23],
réseau de neurones récurrents ou soustraction spectrale [13],
soustraction spectrale adaptative ou non [25].
6 Discussion
6.1 Synthèse
Aspects techniques
Ce mémoire avait pour objectif d’étudier la littérature scientifique autour du sujet de l’amélioration du RSB en sortie d’aides auditives et de la corrélation entre les mesures objectives et subjectives. Nous concluerons en constatant que le travail de réglage d’une aide auditive dans le bruit consiste à trouver un bénéfice en équilibre entre l’amélioration de l’intelligibilité et l’amélioration du confort d’écoute ; les actions des algorithmes de traitement du signal étant contre-productives dans ces deux voies.
Lorsqu’on s’interroge sur le choix prothétique et qu’on sélectionne une gamme d’appareil pour le patient, il est important d’en connaître les avantages et les limites. Ainsi, plusieurs études valident le fonctionnement des aides auditives avancées ou premiums – typiquement les Classes II – mais alertent sur leur faible bénéfice pour la plupart des pertes auditives, dans des conditions réelles.
En outre, les auteurs d’études cliniques concluent fréquemment en rappelant que les résultats ont été obtenus en laboratoire et qu’ils sont reproductibles dans des conditions strictement identiques.
Aspects personnels
La revue de littérature nous apprend à lire avec attention, et en détail, les méthodes, les discussions et les conclusions des études scientifiques. Les résumés qui en sont faits sont, a minima, réducteurs et parfois même trompeurs. S’il y a consensus sur un élément précis d’une étude, on peut constater que ce n’est pas nécessairement sur la nature du sujet. Les contextes de recherche évoluant via la mise en œuvre de progrès technologiques qui deviennent réalité sur le marché, certains résultats d’études prennent tout leur sens bien plus tard.
Par ailleurs, la recherche documentaire est utile pour définir l’étendue de ce qui a été étudié dans des conditions de laboratoire. Ainsi, les futures recherches se nourriront des espaces vides, laissés par des questions sans réponses, pour les combler.
Il a été plusieurs fois question de la mise en œuvre de la méthode Hagerman \& Olofsson dans ce mémoire car nous avions commencé un travail dans ce sens, avant que le contexte sanitaire de 2020 et 2021, lié à l’épidémie de Covid-19, ne vienne le perturber. Sur la base des travaux de Christophe Lesimple – anciennement chercheur en audiologie clinique au sein de Bernafon – sur la visualisation du RSB de sortie7, Xavier Delerce, audioprothésiste D.E., membre du CNA, a complété le script pour réaliser sa “Comparaison des performances dans le bruit des aides auditives de Classe I et de Classe II”8
L’automatisation du code d’analyse écrit en R sous RStudio reste un objectif parallèle à la rédaction de ce mémoire, dont le but est de créer une interface web qui génère notamment les graphes de RSB en entrée et en sortie via la procédure de séparation des sources par inversion de phase. R est un langage de programmation et un logiciel libre destiné aux statistiques et à la science des données. RStudio est un environnement de développement gratuit, libre et multiplateforme pour R. Les packages R sont des extensions du langage. Ils contiennent du code, des données et de la documentation dans un format de collection standardisé qui peut être installé par les utilisateurs, généralement via un référentiel logiciel centralisé tel que CRAN. Voici, pour l’exemple, deux packages utilisés dans le projet :
tuneR9 : analyse la musique et la parole, extrait les caractéristiques telles que les coefficients cepstraux, manipule les fichiers wave et leur représentation, etc.
seewave10 : fournit des fonctions pour l’analyse, la manipulation, l’affichage, la modification et la synthèse de formes d’onde. Effectue l’analyse temporelle, spectrale, de résonance et de corrélation. Génère des spectrogrammes 2D et 3D.
Annexe 1: Liste des revues scientifiques
Table 5: Liste des revues scientifiques citées dans la deuxième partie “Revue de littérature”
Année
SJR
Quartile
Nombre
Nom de la revue de publication
2020
1,577
Q1
13
Ear and Hearing
2020
1,540
Q1
11
Trends In Hearing
2020
0,832
Q1
11
International Journal Of Audiology
2020
0,794
Q2
8
Journal Of The American Academy Of Audiology
2020
0,619
Q1
8
Journal Of The Acoustical Society Of America
2020
0,958
Q1
3
Journal Of Speech, Language, And Hearing Research
2020
2,058
Q1
1
IEEE Signal Processing Magazine
2020
1,389
Q2
1
Hearing Research
2020
1,151
Q1
1
Attention, Perception & Psychophysics
2020
0,990
Q1
1
PLoS ONE
2020
0,947
Q2
1
Frontiers in Psychology
2020
0,937
Q1
1
Clinical And Experimental Otorhinolaryngology
2018
0,926
-
1
IEEE Transactions On Audio, Speech
And Language Processing
2020
0,916
Q1
1
IEEE/ACM Transactions On Audio Speech
And Language Processing
2020
0,688
Q2
1
American Journal Of Audiology
2020
0,459
Q1
1
Speech Communication
2020
0,283
Q1
1
Acta Acustica United With Acustica
2020
0,234
Q2
1
AES: Journal of the Audio Engineering Society
2020
0,193
Q4
1
Medical Journal of Malaysia
2020
0,139
Q4
1
Hearing Journal
La liste est triée par nombre d’occurence décroissant puis par SJR décroissant. La colonne “quartile” correspond à la présence de l’article dans l’un des quatre quartiles de la catégorie de l’article concerné (de Q1=meilleur à Q4=pire).
Annexe 2: Analyse des conclusions des études cliniques
Rappel des sigles et abréviations utilisés : ANL = niveau de bruit acceptable, DIR = directivité, (W)DRC = compression dynamique (large bande), ME = malentendants, NE = normo-entendants, RB = réduction du bruit, RNR = réseau de neurones récurrents, SIB = seuil d’intelligibilité dans le bruit, SS = soustraction spectrale.
Voir la liste complète en début de document.
Table 6: Analyse des conclusions des études cliniques.
Objectif : Effets de la RB et de la DIR sur l’ANL. Conclusion : Les technologies DIR et RB offrent un confort d’écoute en présence de bruit. L’avantage pour l’utilisateur dépend de la façon dont les paramètres de traitement du signal numérique à l’intérieur de l’aide auditive sont ajustés.
Objectif : Évaluation des systèmes de RB dans les aides auditives. Conclusion : Pas de bénéfice à la RB par bande fine, ni en intelligibilité, ni en satisfaction.
Objectif : Effets du temps de retour de la WDRC et du nombre de canaux sur le RSB en sortie et sur l’intelligibilité. Conclusion : Le nombre de canaux a un effet modeste lorsqu’il est analysé à chaque Tr. Les différences individuelles de l’influence sur l’intelligibilité peuvent expliquer ces résultats.
Objectif : Relation entre la fidélité du signal, la perte auditive et la mémoire de travail pour la RB. Conclusion : La fidélité de l’enveloppe est un facteur primordial pour déterminer les effets combinés du bruit et de son traitement sur l’intelligibilité et la qualité de la parole dans un bruit de babil. Le degré de perte auditive et la capacité de la mémoire de travail sont d’importants facteurs expliquant la variabilité des SIB, mais pas des cotes de qualité.
Objectif : Effets perceptifs de la RB par masquage binaire temps-fréquence de la parole bruitée. Conclusion : Bien que le masque binaire idéal améliore l’intelligibilité de la parole dans le bruit, les NE ne le préfèrent pas à la condition non traitée à des RSB de −4 et +4 dB car cela ne semble pas naturel. Avec un algorithme d’estimation du bruit réel comme base de la RB, les erreurs d’estimation annulent l’avantage potentiel sur l’intelligibilité mais peut réduire la gêne sonore perçue, de sorte qu’elle est préférée au signal non traité.
Objectif : Effets perceptifs de la RB en ce qui concerne les préférences personnelles, l’intelligibilité de la parole et l’effort d’écoute. Conclusion : La RB diffère entre les aides auditives. De plus, les individus NE diffèrent dans leur pondération de la gêne sonore et du naturel de la parole.
Objectif : Effets de la RB sur l’intelligibilité de la parole, l’effort d’écoute perçu et les préférences personnelles chez les ME. Conclusion : La RB réduit la gêne due au bruit pour les ME. Les algorithmes préférés sont aussi ceux qui entraînent les SIB les plus faibles.
Objectif : Comparaison acoustique et perceptuelle de la RB et de la DRC dans les appareils auditifs. Conclusion : Les différences de traitement entre les aides auditives sont perceptibles. L’effet de la DRC doit être pris en compte lors du développement et de l’évaluation de la RB des aides auditives.
Objectif : Effet de la RB des aides auditives sur l’effort d’écoute chez les adultes ME. Conclusion : (1) La RB diminue significativement l’effort d’écoute pour les ME plus âgés. (2) La RB n’améliore pas significativement le SIB. (3) Les résultats indiquent que l’effort d’écoute basé sur la performance d’une double tâche est une mesure plus sensible pour évaluer les algorithmes de RB que le SIB.
Objectif : Mesure et prédiction de l’ANL pour les algorithmes de RB à microphone unique. Conclusion : Le test ANL est un outil approprié pour mesurer l’avantage d’un algorithme de RB. La prédiction du ΔANL mesuré individuellement a échoué. Cependant, le ΔANL moyen a pu être prédit avec certaines méthodes. De plus, la perte auditive individuelle doit être prise en compte pour une prédiction plus précise des sujets ME.
Objectif : Effort d’écoute et clarté perçue pour les enfants NE grâce à l’utilisation de la RB. Conclusion : La RB réduit efficacement l’effort d’écoute et améliore les notes de clarté subjectives chez les enfants NE, mais ces améliorations ne sont pas nécessairement liées aux améliorations du RSB de sortie ou à la préservation des spectres de parole.
Objectif : Utilisation du temps de réponse à la parole comme mesure de l’effort d’écoute. Conclusion : Le temps de réponse aux triplets de chiffres diminue considérablement avec l’augmentation des RSB, même lorsque l’intelligibilité de la parole est optimale. Ces différences de temps de réponse pourraient être liées à l’effort d’écoute et, en tant que telles, pourraient être utilisées pour évaluer le traitement du signal des aides auditives à des RSB positifs.
Objectif : Comparaison des effets sur l’intelligibilité subjective et la qualité de la parole dans un babil pour deux algorithmes: un RNR et une SS. Conclusion : Le RNR était significativement préféré à la SS et à l’absence de traitement, à la fois pour l’intelligibilité subjective et la qualité sonore, bien que l’ampleur des préférences était faible. La SS n’était pas significativement préférée à l’absence de traitement pour l’intelligibilité subjective ou la qualité sonore. Les mesures informatiques objectives de l’intelligibilité de la parole prédisaient une meilleure intelligibilité pour le RNR que pour la SS et sans traitement.
Objectif : Évaluation de la DRC combinée à la RB mono-canale pour la mise en œuvre d’aides auditives. Conclusion : Pour les RSB élevés, bien au-dessus du SIB individuel, la combinaison spécifique de la RB mono-canale et de la DRC est perceptuellement pertinente et les approches intégratives (gain de la DRC contrôlé par le gain de la RB) ont été préférées.
Objectif : Évaluation perceptive de la DRC liée au RSB dans les aides auditives. Conclusion : Cette stratégie offre un avantage sur le SIB par rapport à la DRC conventionnelle à action lente et obtient une préférence subjective plus élevée par rapport aux schémas de DRC conventionnelles à action rapide et lente.
Objectif : Les effets des technologies de RB sur l’ANL. Conclusion : La RB a amélioré l’ANL pour chaque type de bruit, et le degré d’amélioration était lié à la valeur de l’ANL de référence. L’amélioration de l’ANL par la RB est perceptible pour les auditeurs, du moins lorsqu’il est examiné dans ce cadre de laboratoire. Les malentendants préfèrent les technologies de RB qui améliorent leur capacité à accepter le bruit.
Objectif : RSB de sortie et perception de la parole dans le bruit : effets de l’algorithme. Conclusion : Bien que les changements significatifs observés dans le RSB résultant de la WDRC et de la RB ne se soient pas convertis en changements dans la perception de la parole, la mesure du RSB peut servir à quantifier la mémoire de travail et la tolérance au bruit.
Objectif : Les effets de la RB sur l’ANL. Conclusion : La RB peut considérablement améliorer l’ANL mesuré cliniquement, ce qui peut entraîner un meilleur confort d’écoute pour les situations de parole dans le bruit.
Objectif : L’ANL comme prédicteur de l’utilisation d’aides auditives. Conclusion : Une analyse par régression a déterminé que l’ANL non appareillé pouvait prédire le succès des aides auditives avec une précision de 85 %.
Objectif : L’effet de l’audibilité, du RSB et des indices temporels de la parole sur l’avantage de la DRC à action rapide dans le bruit modulé. Conclusion : Les performances étaient meilleures avec la DRC qu’avec l’amplification linéaire dans toutes les conditions testées, au moins lorsque le RSB était négatif. D’autres aspects de la déficience auditive que ceux simulés ici sont impliqués dans la dégradation des performances observée chez certains ME avec une DRC à action rapide.
Objectif : Évaluation subjective et objective des algorithmes de gestion du bruit. Conclusion : La DIR et la RB basée sur le SII peuvent améliorer le RSB des environnements d’écoute ; le SIB et l’ANL peuvent être utilisés pour étudier leurs avantages.
Objectif : Bénéfices de la RB en fonction de l’âge pour l’apprentissage de mots à court terme chez les enfants ME. Conclusion : L’apprentissage des mots était significativement réduit chez les jeunes enfants, dans le bruit et en présence de perte auditive. Les bénéfices de la RB en fonction de l’âge étaient significatifs pour les enfants de plus de 10 ans.
Objectif : Effets de la DIR, de la DRC et de la mémoire de travail sur l’intelligibilité. Conclusion : La capacité de la mémoire de travail reste un prédicteur significatif de l’intelligibilité lorsque la DRC et la DIR sont appliquées. La DIR peut réduire l’effet néfaste de la DRC à action rapide sur les signaux vocaux à des RSB plus élevés, ce qui affecte l’intelligibilité. Contrairement à certaines recherches antérieures, cette étude a montré que les personnes ayant une meilleure capacité de mémoire de travail bénéficiaient davantage d’une diminution de la modification du signal que les personnes ayant une moindre capacité de mémoire de travail.
Objectif : Mesures objectives de l’effort d’écoute: effets du bruit de fond et de la RB. Conclusion : À de faibles valeurs de RSB, bien que la RB n’ait aucun effet positif sur le SIB, elle a conduit à de meilleures performances sur la tâche de mémoire de mots et des réponses plus rapides dans les temps de réaction visuelle. Les résultats des deux tâches doubles soutiennent l’hypothèse selon laquelle la RB réduit l’effort d’écoute et libère des ressources cognitives pour d’autres tâches.
Objectif : Effets de la RB sur la perception de la parole chez les enfants ME. Conclusion : Conformément aux résultats d’études précédentes menées auprès d’adultes, les résultats suggèrent que la RB par SS adaptative n’a pas d’effet négatif sur la perception globale de syllabes, de mots ou de phrases sans sens à travers les tranches d’âge (5-10 ans) et de RSB (0, +5 et +10 dB) testés.
Objectif : L’influence de la RB sur l’intelligibilité de la parole, les temps de réponse à la parole et l’effort d’écoute perçu chez les NE. Conclusion : Le temps de réponse pour une tâche arithmétique peut fournir une mesure objective des avantages de la RB. Pour les jeunes NE, une RB à la fois idéale et réaliste peut réduire les temps de réponse aux RSB où l’intelligibilité de la parole est proche de 100 %. La RB idéale peut également réduire l’effort d’écoute perçu.
Objectif : L’efficacité de la fonction de RB des appareils auditifs. Conclusion : Une tolérance accrue au bruit et une meilleure intelligibilité de la parole ont été démontrées avec la RB activée. Bien qu’une RB accrue ait entraîné une tolérance au bruit et une qualité sonore améliorées, la RB la plus agressive n’a pas donné de meilleurs résultats que le niveau inférieur et n’a pas été préférée.
Objectif : L’effet des mécanismes de traitement du signal des aides auditives sur l’ANL: perception et prédiction. Conclusion : Par rapport au traitement linéaire, la WDRC crée une image sonore plus bruyante et rend les auditeurs moins disposés à accepter le bruit. Cependant, cet effet négatif sur l’acceptation du bruit peut être compensé par la RB, quel que soit le mode du microphone. Le RSB de sortie peut prédire l’ANL appareillé à travers différentes combinaisons de RB.
Objectif : Efficacité et efficience des technologies avancées de DIR et de RB pour les personnes âgées ME. Conclusion : Bien que les fonctionnalités premiums de DIR et de RB aient surpassé leurs homologues de base dans des conditions de test de laboratoire bien contrôlées, les avantages n’ont pas été observés dans le monde réel. Les personnes âgées atteintes d’une perte auditive légère à moyenne sont peu susceptibles de percevoir les avantages supplémentaires fournis par les appareils premiums.
Objectif : Configuration de la RB ambiant : effets sur la préférence, la satisfaction et la compréhension de la parole. Conclusion : La RB ambiant améliore considérablement la satisfaction pour le confort d’écoute, la facilité de compréhension de la parole et la qualité sonore.
Annexe 3: Données extraites des études cliniques
Table 7: Données extraites des études cliniques.
Étude
Effectif
Type de surdité
Métriques évaluées
Variables de test
[1]
18
perte auditive neurosensorielle moyenne
confort d’écoute via ANL
type de DIR (omni., dir.), type de RB (multicanale, large bande)
[2]
8
perte auditive neurosensorielle moyenne
SIB, note de qualité
type de bruit (stationnaire, modulé), avec et sans RB par bande fine
[3]
24
perte auditive neurosensorielle légère à moyenne
RSB, SIB
temps de retour DRC, nombre de canaux DRC
[4]
31
perte auditive moyenne à haute fréquence
SIB, note de qualité, mémoire de travail via span test
mesures acoustiques d’influence du traitement, mesure perceptive de détection du traitement, mesure perceptive de la gêne / naturel / préférence
modèle d’appareil, traitement (DRC, RB, DRC+RB)
[9]
12
perte auditive neurosensorielle bilatérale (Δ<15dB entre oreilles)
SIB via R-SPIN, réaction visuelle, mémoire de travail, vitesse de traitement, facilité d’écoute (auto-évaluée)
avec et sans RB
[10]
11
perte auditive moyenne bilatérale
variation de l’ANL, variation du RSB
type de RB sur ordinateur (sans, optimale, simulation d’une RB embarquée, limitée à 6dB puis à 8dB avec estimation du RSB)
10
normo-entendants
idem
idem
[11]
24
normo-entendants
temps de réponse, SIB (reconnaissance de phonèmes), qualité de son (note), mesure de cohérence
avec et sans RB, RSB variable (0 et +5dB)
[12]
12
normo-entendants
identification (reconnaître le dernier chiffre), arithmétique (additionner le 1er et le 3ème, intelligibilité (reconnaître les trois chiffres), mesure des temps de réponse
RSB variable (−6dB, −1dB, +4dB, calme)
[13]
8
perte auditive légère à moyenne
préférence subjective par paires de RSB (intelligibilité et qualité du son), 3 évaluations objectives (STOI notamment), + HASQI
type de RB (sans, SS 5ms, SS 20ms, RNR), rapport parole / babil (de −5dB à +10dB)
[14]
12
perte auditive neurosensorielle bilatérale moyenne (Δ<20dB entre oreilles)
SIB (triplet de digits), temps de réponse en double tâche (identifier le dernier digit et faire l’addition premier et dernier), effort d’écoute (note)
type de RB (masque binaire idéal, estimateur d’erreur quadratique moyenne minimale) RSB variable (de −5dB à \(+\infty\))
[27]
32
perte auditive neurosensorielle
SIB via MHINT (en mandarin), test ANL, note de qualité du son
niveau de RB (off, 8, 14, 20)
[28]
25
perte auditive neurosensorielle
ANL mesuré, ANL prédit
avec et sans RB, type de DRC (linéaire, WDRC), position du bruit (devant, derrière), appareillé ou non
[29]
54
perte auditive légère à moyenne
SIB via HINT, effort d’écoute, qualité du son, localisation, questionnaires (APHAB, SSQ, SADL)
traitement DIR et RB (avec, sans), gamme d’appareil (standard, premium)
[30]
10
perte auditive neurosensorielle ou mixte bilatérale (Δ<20dB entre oreilles)
SIB via HINT, préférence pendant 3 semaines, questionnaires (confort d’écoute, facilité de compréhension, qualité du son)
puissance de la RB ambiant (off, moyenne, forte), comportement de la RB (variable, constant)
Bibliographie
Ahmadi, R., Jalilvand, H., Mahdavi, M. E., Ahmadi, F., & Baghban, A. R. A. (2018). The Effects of Hearing Aid Digital Noise Reduction and Directionality on Acceptable Noise Level. Clinical and Experimental Otorhinolaryngology, 11(4), 267‑274. doi: 10.21053/ceo.2018.00052
Alcántara, J. L., Moore, B. C. J., Kühnel, V., & Launer, S. (2003). Evaluation of the noise reduction system in a commercial digital hearing aid. International Journal of Audiology, 42(1), 34‑42. doi: 10.3109/14992020309056083
Alexander, J. M., & Masterson, K. (2015). Effects of WDRC release time and number of channels on output SNR and speech recognition. Ear and Hearing, 36(2), e35‑49. doi: 10.1097/AUD.0000000000000115
Arehart, K., Souza, P., Kates, J., Lunner, T., & Pedersen, M. S. (2015). Relationship Among Signal Fidelity, Hearing Loss, and Working Memory for Digital Noise Suppression. Ear and Hearing, 36(5), 505‑516. doi: 10.1097/AUD.0000000000000173
Aubreville, M., & Petrausch, S. (2015). Directionality assessment of adaptive binaural beamforming with noise suppression in hearing aids. 211‑215. doi: 10.1109/ICASSP.2015.7177962
Barbour, D. L., Howard, R. T., Song, X. D., Metzger, N., Sukesan, K. A., DiLorenzo, J. C., Snyder, B. R. D., Chen, J. Y., Degen, E. A., Buchbinder, J. M., & Heisey, K. L. (2019). Online Machine Learning Audiometry. Ear and Hearing, 40(4), 918‑926. doi: 10.1097/AUD.0000000000000669
Bell, S. L., Creeke, S. A., & Lutman, M. E. (2010). Measuring real-ear signal-to-noise ratio: application to directional hearing aids. International Journal of Audiology, 49(3), 238‑246. doi: 10.3109/14992020903280146
Bilsen, F. A., Soede, W., & Berkhout, A. J. (1993). Development and assessment of two fixed-array microphones for use with hearing aids. Journal of Rehabilitation Research and Development, 30(1), 73‑81.
Bisgaard, N., Vlaming, M. S. M. G., & Dahlquist, M. (2010). Standard audiograms for the IEC 60118-15 measurement procedure. Trends in Amplification, 14(2), 113‑120. doi: 10.1177/1084713810379609
Blamey, P. J., Fiket, H. J., & Steele, B. R. (2006). Improving speech intelligibility in background noise with an adaptive directional microphone. Journal of the American Academy of Audiology, 17(7), 519‑530. doi: 10.3766/jaaa.17.7.7
Brons, I., Houben, R., & Dreschler, W. A. (2013). Perceptual effects of noise reduction with respect to personal preference, speech intelligibility, and listening effort. Ear and Hearing, 34(1), 29‑41. doi: 10.1097/AUD.0b013e31825f299f
Brons, I., Houben, R., & Dreschler, W. A. (2015). Acoustical and Perceptual Comparison of Noise Reduction and Compression in Hearing Aids. Journal of speech, language, and hearing research: JSLHR, 58(4), 1363‑1376. doi: 10.1044/2015_JSLHR-H-14-0347
Brons, I., Houben, R., & Dreschler, W. A. (2012). Perceptual effects of noise reduction by time-frequency masking of noisy speech. The Journal of the Acoustical Society of America, 132(4), 2690‑2699. doi: 10.1121/1.4747006
Brons, I., Houben, R., & Dreschler, W. A. (2014). Effects of Noise Reduction on Speech Intelligibility, Perceived Listening Effort, and Personal Preference in Hearing-Impaired Listeners. Trends in Hearing, 18, 233121651455392. doi: 10.1177/2331216514553924
Brungart, D. S., Simpson, B. D., Ericson, M. A., & Scott, K. R. (2001). Informational and energetic masking effects in the perception of multiple simultaneous talkers. The Journal of the Acoustical Society of America, 110(5), 2527‑2538. doi: 10.1121/1.1408946
Buss, E., Hall, J. W., & Grose, J. H. (2004). Spectral integration of synchronous and asynchronous cues to consonant identification. The Journal of the Acoustical Society of America, 115(5 Pt 1), 2278‑2285. doi: 10.1121/1.1691035
Carroll, R., Uslar, V., Brand, T., & Ruigendijk, E. (2016). Processing Mechanisms in Hearing-Impaired Listeners: Evidence from Reaction Times and Sentence Interpretation. Ear and Hearing, 37(6), e391‑e401. doi: 10.1097/AUD.0000000000000339
Černý, L., Vokřál, J., & Dlouhá, O. (2018). Influence of age on speech intelligibility in babble noise. Acta Neurobiologiae Experimentalis, 78(2), 140‑147.
Chong, F. Y., & Jenstad, L. M. (2018). Digital noise reduction in hearing aids and its acoustic effect on consonants /s/ and /z/. The Medical Journal of Malaysia, 73(6), 365‑370.
Chung, K. (2012). Comparisons of spectral characteristics of wind noise between omnidirectional and directional microphones. The Journal of the Acoustical Society of America, 131(6), 4508‑4517. doi: 10.1121/1.3699216
Collège national d’audioprothèse (France). (2007). Mesures subjectives : audiométrie vocale en présence de bruit. In L’appareillage de l’adulte. Tome 3, Tome 3, (p. VI pp. 174‑180). les Éd. du Collège national d’audioprothèse.
Compton-Conley, C. L., Neuman, A. C., Killion, M. C., & Levitt, H. (2004). Performance of directional microphones for hearing aids: real-world versus simulation. Journal of the American Academy of Audiology, 15(6), 440‑455. doi: 10.3766/jaaa.15.6.5
Cord, M. T., Surr, R. K., Walden, B. E., & Olson, L. (2002). Performance of directional microphone hearing aids in everyday life. Journal of the American Academy of Audiology, 13(6), 295‑307.
Dahlquist, M., Lutman, M. E., Wood, S., & Leijon, A. (2005). Methodology for quantifying perceptual effects from noise suppression systems. International Journal of Audiology, 44(12), 721‑732. doi: 10.1080/14992020500271712
Delerce, X. (2013). Intelligibilité prédite, intelligibilité perçue 1 ère partie : le SII (Speech Intelligibility Index) en audioprothèse. Les Cahiers de l’Audition, 26(3/2013), 28.
DeSilva, M. D. K., Kooknoor, V., Shetty, H. N., & Thontadarya, S. (2016). Effect of Multichannel and Channels Free Hearing Aid Signal Processing on Phoneme Recognition in Quiet and Noise. International Journal of Health Sciences, 3, 10.
Desjardins, J. L. (2016). The Effects of Hearing Aid Directional Microphone and Noise Reduction Processing on Listening Effort in Older Adults with Hearing Loss. Journal of the American Academy of Audiology, 27(1), 29‑41. doi: 10.3766/jaaa.15030
Dillon, H. (2012). Hearing aids (2. ed). Boomerang Press [u.a.].
Dubbelboer, F., & Houtgast, T. (2007). A detailed study on the effects of noise on speech intelligibility. The Journal of the Acoustical Society of America, 122(5), 2865‑2871. doi: 10.1121/1.2783131
Falk, T. H., Parsa, V., Santos, J. F., Arehart, K., Hazrati, O., Huber, R., Kates, J. M., & Scollie, S. (2015). Objective Quality and Intelligibility Prediction for Users of Assistive Listening Devices: Advantages and limitations of existing tools. IEEE Signal Processing Magazine, 32(2), 114‑124. doi: 10.1109/MSP.2014.2358871
Festen, J. M., & Plomp, R. (1990). Effects of fluctuating noise and interfering speech on the speech‐reception threshold for impaired and normal hearing. The Journal of the Acoustical Society of America, 88(4), 1725‑1736. doi: 10.1121/1.400247
Fortunato, S., Forli, F., Guglielmi, V., De Corso, E., Paludetti, G., Berrettini, S., & Fetoni, A. R. (2016). A review of new insights on the association between hearing loss and cognitive decline in ageing. Acta Otorhinolaryngologica Italica: Organo Ufficiale Della Societa Italiana Di Otorinolaringologia E Chirurgia Cervico-Facciale, 36(3), 155‑166. doi: 10.14639/0392-100X-993
Fortune, T. W., Woodruff, B. D., & Preves, D. A. (1994). A new technique for quantifying temporal envelope contrasts. Ear and Hearing, 15(1), 93‑99. doi: 10.1097/00003446-199402000-00011
Fredelake, S., Holube, I., Schlueter, A., & Hansen, M. (2012). Measurement and prediction of the acceptable noise level for single-microphone noise reduction algorithms. International Journal of Audiology, 51(4), 299‑308. doi: 10.3109/14992027.2011.645075
Garrett, M., Vasilkov, V., Mauermann, M., Wilson, J. L., Henry, K. S., & Verhulst, S. (2020). Speech-in-noise intelligibility difficulties with age: the role of cochlear synaptopathy. bioRxiv, 2020.06.09.142950. doi: 10.1101/2020.06.09.142950
Gnewikow, D., Ricketts, T., Bratt, G. W., & Mutchler, L. C. (2009). Real-world benefit from directional microphone hearing aids. Journal of Rehabilitation Research and Development, 46(5), 603‑618. doi: 10.1682/jrrd.2007.03.0052
Goyette, A., Crukley, J., & Galster, J. (2018). The Effects of Varying Directional Bandwidth in Hearing Aid Users’ Preference and Speech-in-Noise Performance. American Journal of Audiology, 27(1), 95‑103. doi: 10.1044/2017_AJA-17-0063
Greenberg, J. E., & Zurek, P. M. (1992). Evaluation of an adaptive beamforming method for hearing aids. The Journal of the Acoustical Society of America, 91(3), 1662‑1676. doi: 10.1121/1.402446
Gustafson, S., McCreery, R., Hoover, B., Kopun, J. G., & Stelmachowicz, P. (2014). Listening effort and perceived clarity for normal-hearing children with the use of digital noise reduction. Ear and Hearing, 35(2), 183‑194. doi: 10.1097/01.aud.0000440715.85844.b8
Hennequin, R., Khlif, A., Voituret, F., & Moussallam, M. (2020). Spleeter: a fast and efficient music source separation tool with pre-trained models. Journal of Open Source Software, 5, 2154. doi: 10.21105/joss.02154
Holube, I., Fredelake, S., Vlaming, M., & Kollmeier, B. (2010). Development and analysis of an International Speech Test Signal (ISTS). International Journal of Audiology, 49(12), 891‑903. doi: 10.3109/14992027.2010.506889
Holube, I., & Kollmeier, B. (1996). Speech intelligibility prediction in hearing-impaired listeners based on a psychoacoustically motivated perception model. The Journal of the Acoustical Society of America, 100(3), 1703‑1716. doi: 10.1121/1.417354
Hopkins, K., & Moore, B. C. J. (2011). The effects of age and cochlear hearing loss on temporal fine structure sensitivity, frequency selectivity, and speech reception in noise. The Journal of the Acoustical Society of America, 130(1), 334‑349. doi: 10.1121/1.3585848
Hopkins, K., & Moore, B. C. J. (2007). Moderate cochlear hearing loss leads to a reduced ability to use temporal fine structure information. The Journal of the Acoustical Society of America, 122(2), 1055‑1068. doi: 10.1121/1.2749457
Houben, R., Brons, I., & Dreschler, W. A. (2011). A method to remove differences in frequency response between commercial hearing aids to allow direct comparison of the sound quality of hearing-aid features. Trends in Amplification, 15(1), 77‑83. doi: 10.1177/1084713811413303
Houben, R., Doorn-Bierman, M. van, & Dreschler, W. A. (2013). Using response time to speech as a measure for listening effort. International Journal of Audiology, 52(11), 753‑761. doi: 10.3109/14992027.2013.832415
Huber, R., & Kollmeier, B. (2006). PEMO-Q—A New Method for Objective Audio Quality Assessment Using a Model of Auditory Perception. IEEE Transactions on Audio, Speech, and Language Processing, 14(6), 1902‑1911. doi: 10.1109/TASL.2006.883259
Huber, R., Parsa, V., & Scollie, S. (2014). Predicting the perceived sound quality of frequency-compressed speech. PloS One, 9(11), e110260. doi: 10.1371/journal.pone.0110260
Husstedt, H., Mertins, A., & Frenz, M. (2018). Evaluation of Noise Reduction Algorithms in Hearing Aids for Multiple Signals From Equal or Different Directions. Trends in Hearing, 22, 2331216518803198. doi: 10.1177/2331216518803198
Jansen, S., Luts, H., Wagener, K. C., Kollmeier, B., Del Rio, M., Dauman, R., James, C., Fraysse, B., Vormès, E., Frachet, B., Wouters, J., & Wieringen, A. van. (2012). Comparison of three types of French speech-in-noise tests: a multi-center study. International Journal of Audiology, 51(3), 164‑173. doi: 10.3109/14992027.2011.633568
Jenstad, L. M., & Souza, P. E. (2007). Temporal envelope changes of compression and speech rate: combined effects on recognition for older adults. Journal of speech, language, and hearing research: JSLHR, 50(5), 1123‑1138. doi: 10.1044/1092-4388(2007/078)
Kates, J. M. (2010). Understanding compression: Modeling the effects of dynamic-range compression in hearing aids. International Journal of Audiology, 49(6), 395‑409. doi: 10.3109/14992020903426256
Kates, J. M., & Arehart, K. H. (2014a). The Hearing-Aid Speech Quality Index (HASQI) Version 2. AES: Journal of the Audio Engineering Society, 62(3), 99‑117. https://www.aes.org/e-lib/browse.cfm?elib=17126
Kates, J. M., & Arehart, K. H. (2014b). The Hearing-Aid Speech Perception Index (HASPI). Speech Communication, 65, 75‑93. doi: 10.1016/j.specom.2014.06.002
Kates, J. M., Arehart, K. H., Anderson, M. C., Kumar Muralimanohar, R., & Harvey, L. O. J. (2018). Using Objective Metrics to Measure Hearing Aid Performance. Ear and Hearing, 39(6), 1165‑1175. doi: 10.1097/AUD.0000000000000574
Keidser, G., Brew, C., Brewer, S., Dillon, H., Grant, F., & Storey, L. (2005). The preferred response slopes and two-channel compression ratios in twenty listening conditions by hearing-impaired and normal-hearing listeners and their relationship to the acoustic input. International Journal of Audiology, 44(11), 656‑670. doi: 10.1080/14992020500266803
Keshavarzi, M., Goehring, T., Turner, R. E., & Moore, B. C. J. (2019). Comparison of effects on subjective intelligibility and quality of speech in babble for two algorithms: A deep recurrent neural network and spectral subtraction. The Journal of the Acoustical Society of America, 145(3), 1493. doi: 10.1121/1.5094765
Keshavarzi, M., Goehring, T., Zakis, J., Turner, R. E., & Moore, B. C. J. (2018). Use of a Deep Recurrent Neural Network to Reduce Wind Noise: Effects on Judged Speech Intelligibility and Sound Quality. Trends in Hearing, 22, 2331216518770964. doi: 10.1177/2331216518770964
Kortlang, S., Chen, Z., Gerkmann, T., Kollmeier, B., Hohmann, V., & Ewert, S. D. (2018). Evaluation of combined dynamic compression and single channel noise reduction for hearing aid applications. International Journal of Audiology, 57(sup3), S43‑S54. doi: 10.1080/14992027.2017.1300695
Kowalewski, B., Dau, T., & May, T. (2020). Perceptual Evaluation of Signal-to-Noise-Ratio-Aware Dynamic Range Compression in Hearing Aids. Trends in Hearing, 24, 2331216520930531. doi: 10.1177/2331216520930531
Kuyk, S. van, Kleijn, W. B., & Hendriks, R. C. (2018). An Evaluation of Intrusive Instrumental Intelligibility Metrics. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(11), 2153‑2166. doi: 10.1109/TASLP.2018.2856374
Lacher-Fougère, S., & Demany, L. (2005). Consequences of cochlear damage for the detection of interaural phase differences. The Journal of the Acoustical Society of America, 118(4), 2519‑2526. doi: 10.1121/1.2032747
Lai, Y.-H., Li, P.-C., Tsai, K.-S., Chu, W.-C., & Young, S.-T. (2013). Measuring the long-term SNRs of static and adaptive compression amplification techniques for speech in noise. Journal of the American Academy of Audiology, 24(8), 671‑683. doi: 10.3766/jaaa.24.8.4
Lavandier, M., & Culling, J. F. (2008). Speech segregation in rooms: Monaural, binaural, and interacting effects of reverberation on target and interferer. The Journal of the Acoustical Society of America, 123(4), 2237‑2248. doi: 10.1121/1.2871943
Leclercq, F., & Renard, C. (2014). Conception d’un matériel vocal équilibré en difficulté utilisable pour le développement d’un test d’audiométrie vocale dans le bruit [Mémoire audiologie]. Institut Libre Marie Haps (ILMH).
Lesimple, C., Simon, B., & Ag, B. (2018). Hearing aid performance characterized by apparent SNR estimation to predict speech intelligibility in noise with hearing impaired listeners. 1.
Loizou, P. C., & Ma, J. (2011). Extending the articulation index to account for non-linear distortions introduced by noise-suppression algorithms. The Journal of the Acoustical Society of America, 130(2), 986‑995. doi: 10.1121/1.3605668
Lorenzi, C., Gilbert, G., Carn, H., Garnier, S., & Moore, B. C. J. (2006). Speech perception problems of the hearing impaired reflect inability to use temporal fine structure. Proceedings of the National Academy of Sciences of the United States of America, 103(49), 18866‑18869. doi: 10.1073/pnas.0607364103
Lowery, K. J., & Plyler, P. N. (2013). The effects of noise reduction technologies on the acceptance of background noise. Journal of the American Academy of Audiology, 24(8), 649‑659. doi: 10.3766/jaaa.24.8.2
Luts, H., Boon, E., Wable, J., & Wouters, J. (2008). FIST: A French sentence test for speech intelligibility in noise. International Journal of Audiology, 47(6), 373‑374. doi: 10.1080/14992020801887786
MacDonald, E. N., Pichora-Fuller, M. K., & Schneider, B. A. (2010). Effects on speech intelligibility of temporal jittering and spectral smearing of the high-frequency components of speech. Hearing Research, 261(1-2), 63‑66. doi: 10.1016/j.heares.2010.01.005
Mackenzie, E., & Lutman, M. E. (2005). Speech recognition and comfort using hearing instruments with adaptive directional characteristics in asymmetric listening conditions. Ear and Hearing, 26(6), 669‑679. doi: 10.1097/01.aud.0000188185.78217.c5
MacPherson, A., & Akeroyd, M. A. (2014). Variations in the Slope of the Psychometric Functions for Speech Intelligibility: A Systematic Survey. Trends in Hearing, 18, 233121651453772. doi: 10.1177/2331216514537722
Magnusson, L., Claesson, A., Persson, M., & Tengstrand, T. (2013). Speech recognition in noise using bilateral open-fit hearing aids: the limited benefit of directional microphones and noise reduction. International Journal of Audiology, 52(1), 29‑36. doi: 10.3109/14992027.2012.707335
Marrone, N., Mason, C. R., & Kidd, G. (2008). The effects of hearing loss and age on the benefit of spatial separation between multiple talkers in reverberant rooms. The Journal of the Acoustical Society of America, 124(5), 3064‑3075. doi: 10.1121/1.2980441
May, T., Kowalewski, B., & Dau, T. (2018). Signal-to-Noise-Ratio-Aware Dynamic Range Compression in Hearing Aids. Trends in Hearing, 22, 2331216518790903. doi: 10.1177/2331216518790903
McShefferty, D., Whitmer, W. M., & Akeroyd, M. A. (2015). The just-noticeable difference in speech-to-noise ratio. Trends in Hearing, 19. doi: 10.1177/2331216515572316
Miller, C. W., Bentler, R. A., Wu, Y.-H., Lewis, J., & Tremblay, K. (2017). Output signal-to-noise ratio and speech perception in noise: effects of algorithm. International Journal of Audiology, 56(8), 568‑579. doi: 10.1080/14992027.2017.1305128
Moore, B. C. J. (2008). The choice of compression speed in hearing AIDS: theoretical and practical considerations and the role of individual differences. Trends in Amplification, 12(2), 103‑112. doi: 10.1177/1084713808317819
Mueller, H. G., Weber, J., & Hornsby, B. W. Y. (2006). The effects of digital noise reduction on the acceptance of background noise. Trends in Amplification, 10(2), 83‑93. doi: 10.1177/1084713806289553
Nabelek, A. K., Freyaldenhoven, M. C., Tampas, J. W., Burchfiel, S. B., & Muenchen, R. A. (2006). Acceptable noise level as a predictor of hearing aid use. Journal of the American Academy of Audiology, 17(9), 626‑639. doi: 10.3766/jaaa.17.9.2
Naylor, G. (2016). Theoretical Issues of Validity in the Measurement of Aided Speech Reception Threshold in Noise for Comparing Nonlinear Hearing Aid Systems. Journal of the American Academy of Audiology, 27(7), 504‑514. doi: 10.3766/jaaa.15093
Naylor, G., & Johannesson, R. B. (2009). Long-Term Signal-to-Noise Ratio at the Input and Output of Amplitude-Compression Systems. Journal of the American Academy of Audiology, 20(03), 161‑171. doi: 10.3766/jaaa.20.3.2
Ng, E. H. N., Rudner, M., Lunner, T., Pedersen, M. S., & Rönnberg, J. (2013). Effects of noise and working memory capacity on memory processing of speech for hearing-aid users. International Journal of Audiology, 52(7), 433‑441. doi: 10.3109/14992027.2013.776181
Nilsson, M., Soli, S. D., & Sullivan, J. A. (1994). Development of the Hearing In Noise Test for the measurement of speech reception thresholds in quiet and in noise. The Journal of the Acoustical Society of America, 95(2), 1085‑1099. doi: 10.1121/1.408469
Ohlenforst, B., Souza, P. E., & MacDonald, E. N. (2016). Exploring the Relationship Between Working Memory, Compressor Speed, and Background Noise Characteristics. Ear and Hearing, 37(2), 137‑143. doi: 10.1097/AUD.0000000000000240
Ohlenforst, B., Zekveld, A. A., Lunner, T., Wendt, D., Naylor, G., Wang, Y., Versfeld, N. J., & Kramer, S. E. (2017). Impact of stimulus-related factors and hearing impairment on listening effort as indicated by pupil dilation. Hearing Research, 351, 68‑79. doi: 10.1016/j.heares.2017.05.012
Olsen, H. L., Olofsson, A., & Hagerman, B. (2005). The effect of audibility, signal-to-noise ratio, and temporal speech cues on the benefit from fast-acting compression in modulated noise. International Journal of Audiology, 44(7), 421‑433. doi: 10.1080/14992020500175855
Pals, C., Sarampalis, A., Rijn, H. van, & Başkent, D. (2015). Validation of a simple response-time measure of listening effort. The Journal of the Acoustical Society of America, 138(3), EL187‑192. doi: 10.1121/1.4929614
Paquier, M. (2013). Traitement du bruit et de la parole par le système auditif chez l’entendant et le déficient auditif. Les Cahiers de l’audition, 26(6), 17‑21.
Park, H.-S., Moon, I. J., Jin, S. H., Choi, J. E., Cho, Y.-S., & Hong, S. H. (2015). Benefit From Directional Microphone Hearing Aids: Objective and Subjective Evaluations. Clinical and Experimental Otorhinolaryngology, 8(3), 237‑242. doi: 10.3342/ceo.2015.8.3.237
Paul, B. T., Waheed, S., Bruce, I. C., & Roberts, L. E. (2017). Subcortical amplitude modulation encoding deficits suggest evidence of cochlear synaptopathy in normal-hearing 18–19 year olds with higher lifetime noise exposure. The Journal of the Acoustical Society of America, 142(5), EL434‑EL440. doi: 10.1121/1.5009603
Peeters, H., Kuk, F., Lau, C.-c., & Keenan, D. (2009). Subjective and Objective Evaluation of Noise Management Algorithms. Journal of the American Academy of Audiology, 20(02), 089‑098. doi: 10.3766/jaaa.20.2.2
Pichora-Fuller, M. K. (2015). Cognitive Decline and Hearing Health Care for Older Adults. American Journal of Audiology, 24(2), 108‑111. doi: 10.1044/2015_AJA-14-0076
Picou, E. M., & Ricketts, T. A. (2019). An Evaluation of Hearing Aid Beamforming Microphone Arrays in a Noisy Laboratory Setting. Journal of the American Academy of Audiology, 30(2), 131‑144. doi: 10.3766/jaaa.17090
Pittman, A. (2011). Age-related benefits of digital noise reduction for short-term word learning in children with hearing loss. Journal of speech, language, and hearing research: JSLHR, 54(5), 1448‑1463. doi: 10.1044/1092-4388(2011/10-0341)
Plomp, R. (1994). Noise, amplification, and compression: considerations of three main issues in hearing aid design. Ear and Hearing, 15(1), 2‑12.
Preminger, J., & Wiley, T. L. (1985). Frequency selectivity and consonant intelligibility in sensorineural hearing loss. Journal of Speech and Hearing Research, 28(2), 197‑206. doi: 10.1044/jshr.2802.197
Pumford, J. M., Seewald, R. C., Scollie, S. D., & Jenstad, L. M. (2000). Speech recognition with in-the-ear and behind-the-ear dual-microphone hearing instruments. Journal of the American Academy of Audiology, 11(1), 23‑35.
Rafii, Z., Liutkus, A., Stöter, F.-R., Mimilakis, S. I., FitzGerald, D., & Pardo, B. (2018). An Overview of Lead and Accompaniment Separation in Music. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(8), 1307‑1335. doi: 10.1109/TASLP.2018.2825440
Rallapalli, V., Ellis, G., & Souza, P. (2020). Effects of Directionality, Compression, and Working Memory on Speech Recognition. Ear and Hearing, 42(3), 492‑505. doi: 10.1097/AUD.0000000000000970
Rhebergen, K. S., Maalderink, T. H., & Dreschler, W. A. (2017). Characterizing Speech Intelligibility in Noise After Wide Dynamic Range Compression. Ear and Hearing, 38(2), 194‑204. doi: 10.1097/AUD.0000000000000369
Rhebergen, K. S., & Versfeld, N. J. (2005). A Speech Intelligibility Index-based approach to predict the speech reception threshold for sentences in fluctuating noise for normal-hearing listeners. The Journal of the Acoustical Society of America, 117(4), 2181‑2192. doi: 10.1121/1.1861713
Sang, J., Hu, H., Zheng, C., Li, G., Lutman, M. E., & Bleeck, S. (2015). Speech quality evaluation of a sparse coding shrinkage noise reduction algorithm with normal hearing and hearing impaired listeners. Hearing Research, 327, 175‑185. doi: 10.1016/j.heares.2015.07.019
Sarampalis, A., Kalluri, S., Edwards, B., & Hafter, E. (2009). Objective measures of listening effort: effects of background noise and noise reduction. Journal of speech, language, and hearing research: JSLHR, 52(5), 1230‑1240. doi: 10.1044/1092-4388(2009/08-0111)
Schijndel, N. H. van, Houtgast, T., & Festen, J. M. (2001). Effects of degradation of intensity, time, or frequency content on speech intelligibility for normal-hearing and hearing-impaired listeners. The Journal of the Acoustical Society of America, 110(1), 529‑542. doi: 10.1121/1.1378345
Smeds, K., Leijon, A., Wolters, F., Hammarstedt, A., Båsjö, S., & Hertzman, S. (2014). Comparison of predictive measures of speech recognition after noise reduction processing. The Journal of the Acoustical Society of America, 136(3), 1363. doi: 10.1121/1.4892766
Smeds, K., Wolters, F., & Rung, M. (2015). Estimation of Signal-to-Noise Ratios in Realistic Sound Scenarios. Journal of the American Academy of Audiology, 26(2), 183‑196. doi: 10.3766/jaaa.26.2.7
Souza, P., Arehart, K., & Neher, T. (2015). Working Memory and Hearing Aid Processing: Literature Findings, Future Directions, and Clinical Applications. Frontiers in Psychology, 6, 1894. doi: 10.3389/fpsyg.2015.01894
Souza, P. E. (2002). Effects of compression on speech acoustics, intelligibility, and sound quality. Trends in Amplification, 6(4), 131‑165. doi: 10.1177/108471380200600402
Souza, P. E., Jenstad, L. M., & Boike, K. T. (2006). Measuring the acoustic effects of compression amplification on speech in noise. The Journal of the Acoustical Society of America, 119(1), 41‑44. doi: 10.1121/1.2108861
Stelmachowicz, P., Lewis, D., Hoover, B., Nishi, K., McCreery, R., & Woods, W. (2010). Effects of digital noise reduction on speech perception for children with hearing loss. Ear and Hearing, 31(3), 345‑355. doi: 10.1097/AUD.0b013e3181cda9ce
Tillaart-Haverkate, M. van den, Ronde-Brons, I. de, Dreschler, W. A., & Houben, R. (2017). The Influence of Noise Reduction on Speech Intelligibility, Response Times to Speech, and Perceived Listening Effort in Normal-Hearing Listeners. Trends in Hearing, 21, 2331216517716844. doi: 10.1177/2331216517716844
Vaillancourt, V., Laroche, C., Mayer, C., Basque, C., Nali, M., Eriks-Brophy, A., Soli, S. D., & Giguère, C. (2005). Adaptation of the HINT (hearing in noise test) for adult Canadian Francophone populations. International Journal of Audiology, 44(6), 358‑361. doi: 10.1080/14992020500060875
Valente, M., Fabry, D. A., & Potts, L. G. (1995). Recognition of speech in noise with hearing aids using dual microphones. Journal of the American Academy of Audiology, 6(6), 440‑449.
Valin, J.-M. (2018). A Hybrid DSP/Deep Learning Approach to Real-Time Full-Band Speech Enhancement. 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), 1‑5. doi: 10.1109/MMSP.2018.8547084
Wingfield, A. (2016). Evolution of Models of Working Memory and Cognitive Resources. Ear and Hearing, 37 Suppl 1, 35S‑43S. doi: 10.1097/AUD.0000000000000310
Wong, L. L. N., Chen, Y., Wang, Q., & Kuehnel, V. (2018). Efficacy of a Hearing Aid Noise Reduction Function. Trends in Hearing, 22, 2331216518782839. doi: 10.1177/2331216518782839
Wu, Y.-H., & Stangl, E. (2013). The effect of hearing aid signal-processing schemes on acceptable noise levels: perception and prediction. Ear and Hearing, 34(3), 333‑341. doi: 10.1097/AUD.0b013e31827417d4
Wu, Y.-H., Stangl, E., Chipara, O., Hasan, S. S., DeVries, S., & Oleson, J. (2019). Efficacy and Effectiveness of Advanced Hearing Aid Directional and Noise Reduction Technologies for Older Adults With Mild to Moderate Hearing Loss. Ear and Hearing, 40(4), 805‑822. doi: 10.1097/AUD.0000000000000672
Wu, Y.-H., Stangl, E., Zhang, X., Perkins, J., & Eilers, E. (2016). Psychometric Functions of Dual-Task Paradigms for Measuring Listening Effort. Ear and Hearing, 37(6), 660‑670. doi: 10.1097/AUD.0000000000000335
Zakis, J. A., Hau, J., & Blamey, P. J. (2009). Environmental noise reduction configuration: Effects on preferences, satisfaction, and speech understanding. International Journal of Audiology, 48(12), 853‑867. doi: 10.3109/14992020903131117
Zakis, J. A., & Wise, C. (2007). The acoustic and perceptual effects of two noise-suppression algorithms. The Journal of the Acoustical Society of America, 121(1), 433‑441. doi: 10.1121/1.2401656
Zekveld, A. A., Kramer, S. E., & Festen, J. M. (2010). Pupil response as an indication of effortful listening: the influence of sentence intelligibility. Ear and Hearing, 31(4), 480‑490. doi: 10.1097/AUD.0b013e3181d4f251
Zychaluk, K., & Foster, D. H. (2009). Model-free estimation of the psychometric function. Attention, Perception & Psychophysics, 71(6), 1414‑1425. doi: 10.3758/APP.71.6.1414